搜索到
6
篇与
的结果
-
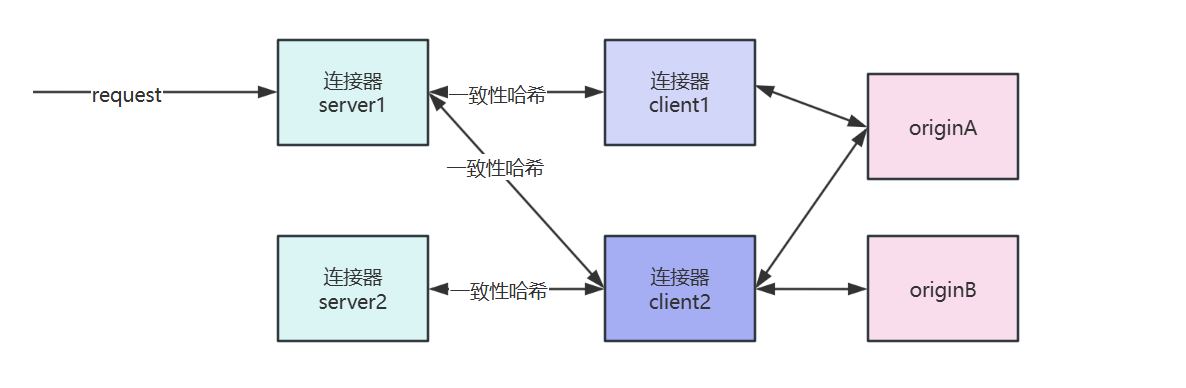
![The Problem of Uneven Distribution in Consistent Hashing]() The Problem of Uneven Distribution in Consistent Hashing {collapse}{collapse-item label="一、背景" open}1.线上出现连接器server多个IP一致性哈希到了同一个连接器client id上,导致请求都代理到了一个连接器client上。一致性哈希算法实现的https://github.com/stathat/consistent 针对这个库做一些优化{/collapse-item}{collapse-item label="二、优化方案" open}1.增加哈希环上的虚拟节点个数每个新增节点对应虚拟节点从20依次增加虚拟节点个数连接器实例uuid个数哈希的ip个数方差ip哈希总耗时20100100001493.72ms100100100001018.962ms20010010000727.863ms30010010000515.463ms50010010000250.524ms2.修改生成虚拟节点哈希时的字符串生成哈希字符串连接器实例uuid个数哈希的ip个数方差连接器实例id+虚拟节点序号100100001692连接器实例id+虚拟节点序号+1-100随机数10010000588.74连接器实例id+虚拟节点序号+1-1000随机数10010000517.12连接器实例id+虚拟节点序号+时间戳10010000706.743.同时新增虚拟节点和修改哈希的字符串虚拟节点个数生成哈希字符串连接器实例uuid个数哈希ip个数方差公网ip哈希总耗时20连接器实例id+虚拟节点序号100100001521.82ms50连接器实例id+虚拟节点序号+1-1000随机数10010000328.12ms100连接器实例id+虚拟节点序号+1-1000随机数10010000209.12ms150连接器实例id+虚拟节点序号+1-1000随机数10010000156.162ms200连接器实例id+虚拟节点序号+1-1000随机数10010000144.743ms300连接器实例id+虚拟节点序号+1-1000随机数10010000147.323ms4.修改哈希算法查询100000次哈希算法分布离均匀值得偏差总耗时Murmur30.8%15.602msCRC326%20.1744ms特性CRC32Murmur3设计初衷数据校验(错误检测)哈希表/散列优化设计目标检测传输错误(如网络包校验)实现均匀的键值分布雪崩效应弱(微小输入变化→微小输出变化)强(微小输入变化→巨大输出变化)算法特性对比{card-describe title="CRC32的问题"}多项式校验特性:CRC32基于多项式除法,设计目标是检测突发错误(如连续比特错误)对相似输入(如连续数字ID)会产生相似的哈希值示例:CRC32("user100") 和 CRC32("user101") 可能只有最后几位不同由于构建哈希环虚拟节点使用的key是id+自增序号会导致哈希值非常相似{/card-describe}Murmur3的优势{alert type="info"}结合乘法、移位、异或等操作打乱数据 对输入数据的每个字节进行多次混合运算{/alert}雪崩效应:murmur3("user100") → 0x58a7f2d1 murmur3("user101") → 0x3c8bf0e7 # 输入微小变化导致输出完全不同{/collapse-item}{collapse-item label="三、结论" open}测试发现选择虚拟节点数150,生成哈希字符串选择连接器实例id+虚拟节点序号+1-1000随机数,相对来说,哈希到的连接器id相对均匀一些每个连接器id被哈希到的平均次数时100次,从哈希出来的结果来看相对均匀。由于连接器server是分布式的 每台节点随机值不一样会导致构建的哈希环不一样,故只能增加一致性哈希的虚拟节点修改key的哈希算法不使用CRC32改成murmur3{/collapse-item}{/collapse}
The Problem of Uneven Distribution in Consistent Hashing {collapse}{collapse-item label="一、背景" open}1.线上出现连接器server多个IP一致性哈希到了同一个连接器client id上,导致请求都代理到了一个连接器client上。一致性哈希算法实现的https://github.com/stathat/consistent 针对这个库做一些优化{/collapse-item}{collapse-item label="二、优化方案" open}1.增加哈希环上的虚拟节点个数每个新增节点对应虚拟节点从20依次增加虚拟节点个数连接器实例uuid个数哈希的ip个数方差ip哈希总耗时20100100001493.72ms100100100001018.962ms20010010000727.863ms30010010000515.463ms50010010000250.524ms2.修改生成虚拟节点哈希时的字符串生成哈希字符串连接器实例uuid个数哈希的ip个数方差连接器实例id+虚拟节点序号100100001692连接器实例id+虚拟节点序号+1-100随机数10010000588.74连接器实例id+虚拟节点序号+1-1000随机数10010000517.12连接器实例id+虚拟节点序号+时间戳10010000706.743.同时新增虚拟节点和修改哈希的字符串虚拟节点个数生成哈希字符串连接器实例uuid个数哈希ip个数方差公网ip哈希总耗时20连接器实例id+虚拟节点序号100100001521.82ms50连接器实例id+虚拟节点序号+1-1000随机数10010000328.12ms100连接器实例id+虚拟节点序号+1-1000随机数10010000209.12ms150连接器实例id+虚拟节点序号+1-1000随机数10010000156.162ms200连接器实例id+虚拟节点序号+1-1000随机数10010000144.743ms300连接器实例id+虚拟节点序号+1-1000随机数10010000147.323ms4.修改哈希算法查询100000次哈希算法分布离均匀值得偏差总耗时Murmur30.8%15.602msCRC326%20.1744ms特性CRC32Murmur3设计初衷数据校验(错误检测)哈希表/散列优化设计目标检测传输错误(如网络包校验)实现均匀的键值分布雪崩效应弱(微小输入变化→微小输出变化)强(微小输入变化→巨大输出变化)算法特性对比{card-describe title="CRC32的问题"}多项式校验特性:CRC32基于多项式除法,设计目标是检测突发错误(如连续比特错误)对相似输入(如连续数字ID)会产生相似的哈希值示例:CRC32("user100") 和 CRC32("user101") 可能只有最后几位不同由于构建哈希环虚拟节点使用的key是id+自增序号会导致哈希值非常相似{/card-describe}Murmur3的优势{alert type="info"}结合乘法、移位、异或等操作打乱数据 对输入数据的每个字节进行多次混合运算{/alert}雪崩效应:murmur3("user100") → 0x58a7f2d1 murmur3("user101") → 0x3c8bf0e7 # 输入微小变化导致输出完全不同{/collapse-item}{collapse-item label="三、结论" open}测试发现选择虚拟节点数150,生成哈希字符串选择连接器实例id+虚拟节点序号+1-1000随机数,相对来说,哈希到的连接器id相对均匀一些每个连接器id被哈希到的平均次数时100次,从哈希出来的结果来看相对均匀。由于连接器server是分布式的 每台节点随机值不一样会导致构建的哈希环不一样,故只能增加一致性哈希的虚拟节点修改key的哈希算法不使用CRC32改成murmur3{/collapse-item}{/collapse} -
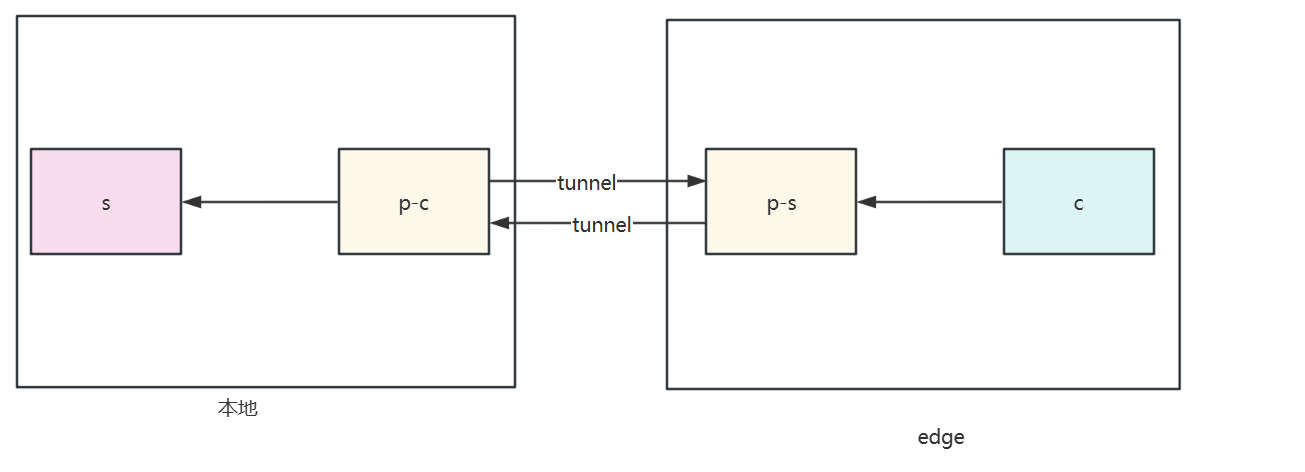
![Proxy Protocol Performance Testing Comparison(yamux/smux/h2)]() Proxy Protocol Performance Testing Comparison(yamux/smux/h2) 测试环境测试组件包括:请求发起端(client)、请求接收端(server)和代理组件客户端(proxy client)和代理组件服务端(proxy server)。测试目的:对比proxy client和proxy serve之间使用不同的协议对请求的影响。将client -> proxy client和proxy server -> server之间的网络影响降至最低,所以测试时将client和proxy client放在同一台主机host1上,将proxy server和server放在同一台主机host2上。两台4C8G的linux设备测试结果下面测试为proxy client 和 proxy server之间没有丢包的情况下,分别测试proxy client 和 proxy server之间的RTT为10ms、100ms、200ms、500ms情况下,四种协议的单个请求的平均耗时(总请求数量为10000)。{lamp/}RTT 10ms{lamp/}RTT 100ms{lamp/}RTT 200ms{lamp/}RTT 500ms前3000个请求是因为需要openstream导致的 建立了1000的并发建立了1000个stream,每个stream发送10个请求,去除建立stream的10ms rtt数据如下{lamp/}拉流传输性能iperf3测试一分钟传输性能每秒大概发送500MB数据测试传输数据不同延时下载大文件{lamp/}h2RTT/1G文件speedtime<1ms223MB/s4.6s100ms28.7MB/s54s500ms6.32MB/s3m 8syamuxRTT/1G文件speedtime<1ms144MB/s7.0s100ms9.71MB/s1m 49s500ms1.98MB/s8m 42stcpRTT/1G文件speedtime<1ms256MB/s4.1s100ms29.1MB/s36s500ms6.33MB/s2m 57s结论:随着代理组件(proxy client和proxy server)间的RTT增大,smux、http2的单个请求平均耗时差距小。smux 在传输性能和最大带宽方面表现最佳,但其波动稍大于 h2。h2 在传输稳定性方面表现最佳,其平均带宽和最大带宽也很高。yamux 的平均带宽和稳定性较差,可能不太适合高性能要求的场景。
Proxy Protocol Performance Testing Comparison(yamux/smux/h2) 测试环境测试组件包括:请求发起端(client)、请求接收端(server)和代理组件客户端(proxy client)和代理组件服务端(proxy server)。测试目的:对比proxy client和proxy serve之间使用不同的协议对请求的影响。将client -> proxy client和proxy server -> server之间的网络影响降至最低,所以测试时将client和proxy client放在同一台主机host1上,将proxy server和server放在同一台主机host2上。两台4C8G的linux设备测试结果下面测试为proxy client 和 proxy server之间没有丢包的情况下,分别测试proxy client 和 proxy server之间的RTT为10ms、100ms、200ms、500ms情况下,四种协议的单个请求的平均耗时(总请求数量为10000)。{lamp/}RTT 10ms{lamp/}RTT 100ms{lamp/}RTT 200ms{lamp/}RTT 500ms前3000个请求是因为需要openstream导致的 建立了1000的并发建立了1000个stream,每个stream发送10个请求,去除建立stream的10ms rtt数据如下{lamp/}拉流传输性能iperf3测试一分钟传输性能每秒大概发送500MB数据测试传输数据不同延时下载大文件{lamp/}h2RTT/1G文件speedtime<1ms223MB/s4.6s100ms28.7MB/s54s500ms6.32MB/s3m 8syamuxRTT/1G文件speedtime<1ms144MB/s7.0s100ms9.71MB/s1m 49s500ms1.98MB/s8m 42stcpRTT/1G文件speedtime<1ms256MB/s4.1s100ms29.1MB/s36s500ms6.33MB/s2m 57s结论:随着代理组件(proxy client和proxy server)间的RTT增大,smux、http2的单个请求平均耗时差距小。smux 在传输性能和最大带宽方面表现最佳,但其波动稍大于 h2。h2 在传输稳定性方面表现最佳,其平均带宽和最大带宽也很高。yamux 的平均带宽和稳定性较差,可能不太适合高性能要求的场景。 -
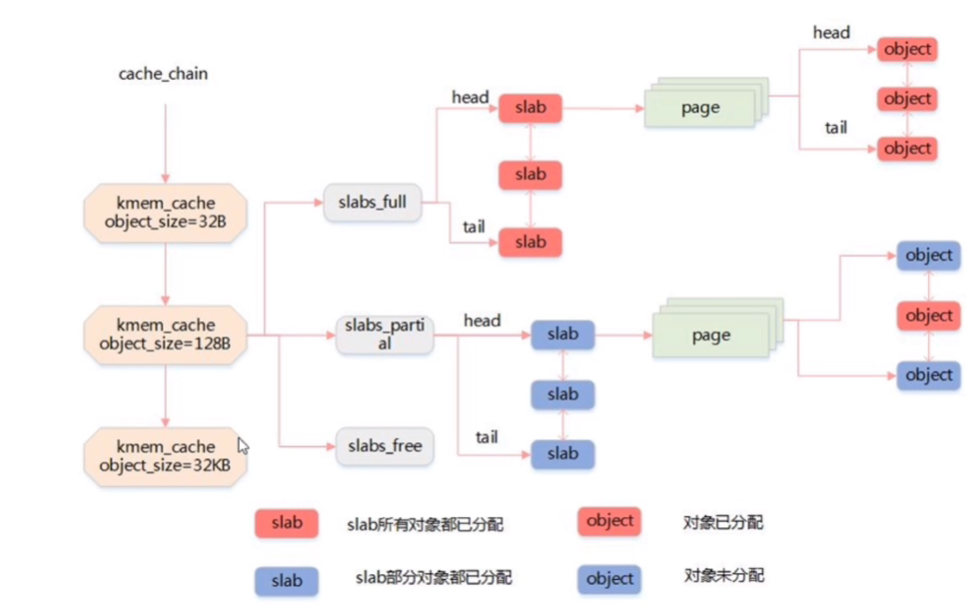
![The Art of Memory Allocation: Malloc, Slab, C++ STL, and GoLang Memory Allocation]() The Art of Memory Allocation: Malloc, Slab, C++ STL, and GoLang Memory Allocation 在现代编程中,内存管理是一个核心且复杂的话题。本文将探讨不同语言和环境下内存分配器的实现,包括传统的malloc,Slab分配器,C++ STL内存分配器,以及GoLang的内存分配机制。我们的目标是理解这些内存分配器背后的设计思想和底层原理。今天在看到golang的内存配分机制,突然想到以前看过的一些内存分配的底层原理,正好可以一起整理下。{collapse}{collapse-item label="1. 内存分配器设计概念 " open} 内存分配器的设计首先考虑的是如何组织和管理空闲块。这涉及到空闲块的存放、分割和合并等操作。成功的内存管理不仅需要有效地分配和释放内存,还需要尽量减少内存碎片。空闲块的组织是个学问,操作系统中常见的空闲块组织的策略分为隐式空闲链表、显式空闲链表、分离的空闲链表三种,现在很多内存分配器中用的最多的还是分离空闲链表居多。空闲块组织方式策略隐式空闲链表空闲块是通过头部中的大小字段隐含地连接着,强制的系统对齐要求,分配器对块格式的选择会对分配器上的最小块大小有强制要求显示空闲链表新释放的块放置在链表的开始处,链表中的每个块的地址都小于它后继的地址分离的空闲链表维护多个空闲链表,其中每个链表中的块有大致相等的大小,将所有可能的块大小分成大小类,简单分离存储、分离适配、伙伴系统分离的空闲链表分配释放简单分离存储只分配释放,不分割合并分配时从相应空闲链表中选择第一块的全部,释放时直接将块插入到相应空闲链表的头部分离适配查找适当的空闲链表做首次适配,查找到一个合适的块,如果找到就可选的分割它,将剩余部分插入到适当的空闲链表中找不到合适的块,就搜索下一个更大的空闲链表,如果空闲链表中没有合适的块,那么就向操作系统中请求额外的堆内存,从这个新的堆内存中分配出一个块,剩余部分放置在适当的空闲链表中执行合并,将结果放置到相应的空闲链表伙伴系统每个大小类都是2的幂,请求块大小向上舍入到最接近2的幂,将一个内存块二分直至等于请求块大小,剩余的半块放置到相应的空闲链表中给定块地址和大小就可以知道伙伴的地址,不断合并空闲伙伴,遇到已分配伙伴就停止合并{/collapse-item}{collapse-item label="2. 经典的Malloc实现" open} 在C语言中,malloc()函数是动态内存分配的基石。这个函数通常使用glibc的ptmalloc2实现。然而,tcmalloc(来自Google)和jemalloc(来自Facebook)等现代分配器在性能和减少内存碎片方面有显著优势,尤其是在多线程环境下。malloc内存池的实现2.1 分配的内存大小小于512字节,则通过内存大小定位到small bins对应的index上,大小整除8为索引2.2 如果对应的bins上有空闲块,返回2.3 如果对应的bins上没有空闲块,则遍历unsorted list,查找合适大小的空闲块,找到则返回,未找到,将unsorted list中的块归类到small bins和large bins,index++,查找更大的链表,找到则返回,剩下的加入到unsorted list,否则使用top chunk2.4 如果还未找到空闲块,则会根据需要申请的内存大小来使用分配策略,内存小于128k使用brk,内存大于128k,使用mmap2.1如果分配内存大小大于512字节,定位到large bins对应的index上,跳到2.2free释放的chunk是否与top chunk相邻,相邻则合并释放的chunk是否与top chunk不相邻,插入到unsorted list{/collapse-item}{collapse-item label=" 3. Slab分配器" open} Slab分配器主要用于内核内存分配,其主要思想是缓存常用对象以减少初始化和销毁成本。Slab分配器通过维护一组预先分配的对象"slabs"来实现这一点,这大大加速了分配过程。slab分配器高效的解决了内碎和外碎的问题,解决外碎的主要方式是把所有的空闲物理页分组为11块链表,每块链表分别包含大小为1,2,4,8,16...1024个连续的物理页,每个页常规大小是4096(4k),页帧(物理页)的分配由伙伴系统进行解决内碎的方式是对于频繁地分配和释放的数据结构,会缓存它,对象析构仅是标记slab的数据结构如下 高速缓存组(链表),每一个高速缓存里面存储着对象的大小,3个slab链表,每个链表的节点是一个slab,每个slab包含了一个或多个物理页,每个物理页存储着高速缓冲对应的对象大小,每一个高速缓存有三种状态的full、partial、free的slab对象的链表{/collapse-item}{collapse-item label="4. C++ STL内存分配器 " open} C++标准模板库(STL)提供了一套灵活的内存分配器接口。STL内存分配器可以定制,支持不同类型的内存分配策略,这对于优化性能和内存使用非常有用。c++ stl内存分配器 new 调用operator new配置内存 调用对象构造函数构造对象内容 delete 调用对象析构函数 调用成员的operator delete释放内存空间分配器SGI标准的空间配置器 效率不佳,只是将c++的new,delete薄薄的包装了一层 allocate deallocateSGI特殊的空间配置器 将new和delete两个阶段的操作分开来 alloc::allocate(num) 为num个元素分配内存 alloc::deallocate(p, num) 回收p所指的“可容纳num个元素”的内存空间 ::construct(p, val) 将p所指的元素初始化为val ::destroy(p)/::destroy(first, last) 销毁p所指的元素/销毁迭代器所指的区间第一级配置器 alloc::allocate(num) 使用malloc分配内存,分配失败则改用oom_malloc, oom_malloc将不断调用客户端设置的内存不足例程,不断尝试释放、配置,如果客户端未设置该函数将抛出异常bad_alloc或利用exit(0)终止程序 alloc::deallocate(p, num) 直接使用free第二级配置器 次层配置,提升内存管理的效率,减小内存造成的内存碎片问题 分配:分配空间大小超过128bytes时,会使用第一级空间配置器,直接使用malloc relloc free,如果分配不成功则调用句柄释放一部分内存,如果还不能成功则抛出异常分配空间大小小于128bytes时,会使用第二级空间配置器,内存池和空闲链表 内存池管理:每次配置一大块内存,并且维护对应的16个空闲链表。16个空闲链表分别管理大小为8、16、24...120、128的数据块。数据结构 空闲链表节点实现,共用体的形式既可以存储下一个空闲节点又可以存储当前分配给客户使用的数据,当分配给客户时,将不需要记录到空闲链表中 内存池的开始位置、结束位置 alloc::allocate(num) 调用将用户申请的字节数扩大到8的倍数,,然后在自由链表中找到对应大小的子链表,找到有内存直接返回空闲链表头结点,空闲链表结点移动到下一个空闲结点,没有找到则调用refill()准备为freelist重新填充空间,新的空间将取自内存池(经由chunk_alloc完成),chunk_alloc缺省取得20个新节点,,根据内存池开始位置和结束位置来判断容量,但万一内存池空间不足,获得的节点可能小于20.如果块数不够20块,那尽可能的分配最多的块数给自由链表,并且更新每次申请的块数。如果一块都不够则把剩余的内存挂到自由链表,然后向系统heap申请空间,申请的大小为需求量的两倍,再加上一个随着申请次数递增的附加量,如果堆上malloc分配失败,chunk_alloc会从空闲链表中寻找更大的数据块分配给内存池,chunk_alloc递归调用,递归调用山穷水尽之后,则调用一级空间配置器,虽然也是malloc,不过一级空间配置器有out-of-memory处理机制,或许有机会释放一些空间,可以就成功 ,失败就抛出bad_alloc异常alloc::deallocate(p, num) 如果释放的内存大于128bytes时,调用free 如果释放的内存小于128bytes时,找到合适的自由链表插入{/collapse-item}{collapse-item label=" 5. GoLang内存分配实现" open} GoLang实现了自己的内存分配器,其原理与tcmalloc类似。它维护一块大的全局内存,每个线程(在GoLang中称为P)维护一块小的私有内存。当私有内存不足时,线程会从全局内存申请。内存结构: GoLang在启动时向系统申请一大块内存,这块内存被划分为spans、bitmap、arena三个部分。arena是堆区,用于分配应用所需内存,而spans和bitmap则用于管理arena区。Span的角色: Span是内存管理的基本单位,每个span可以包含一个或多个连续的页。为了满足小对象的分配,span中的一页可以进一步划分为更小的单元。对于大对象,可以通过多页span来实现。Class的分配: GoLang根据对象的大小划分了多个class,每个class代表一个固定大小的对象和每个span的大小。这种分类有助于优化内存分配效率和减少碎片。mcache和mcentral: GoLang为每个线程分配了span的缓存(mcache),这些缓存的资源来自于全局的mcentral。mcentral管理多个span供线程申请使用。内存分配过程: 当线程需要内存时,它会首先在mcache中寻找可用的span。如果mcache中没有可用的span,则从mcentral请求。如果mcentral也没有可用的span,则从全局的mheap中申请新的span。golang程序启动的时候会向系统申请内存如下 预申请的内存划分为spans、bitmap、arena三部分。其中arena即为所谓的堆区,应用中需要的内存从这里分配。其中spans和bitmap是为了管理arena区而存在的。arena的大小为512G,为了方便管理把arena区域划分成一个个的page,每个page为8KB,一共有512GB/8KB个页;spans区域存放span的指针,每个指针对应一个page,所以span区域的大小为(512GB/8KB)*指针大小8byte = 512Mbitmap区域大小也是通过arena计算出来,不过主要用于GC。span span是用于管理arena页的关键数据结构,每个span中包含1个或多个连续页,为了满足小对象分配,span中的一页会划分更小的粒度,而对于大对象比如超过页大小,则通过多页实现。 class 跟据对象大小,划分了一系列class,每个class都代表一个固定大小的对象,以及每个span的大小// class bytes/obj bytes/span objects waste bytes // 1 8 8192 1024 0 // 2 16 8192 512 0 // 3 32 8192 256 0 // 4 48 8192 170 32 // .... // 66 32768 32768 1 0上表中每列含义如下:class: class ID,每个span结构中都有一个class ID, 表示该span可处理的对象类型bytes/obj:该class代表对象的字节数bytes/span:每个span占用堆的字节数,也即页数*页大小objects: 每个span可分配的对象个数,也即(bytes/spans)/(bytes/obj)waste bytes: 每个span产生的内存碎片,也即(bytes/spans)%(bytes/obj)上表可见最大的对象是32K大小,超过32K大小的由特殊的class表示,该class ID为0,每个class只包含一个对象。src/runtime/mheap.go:mspan 定义了其数据结构:type mspan struct { next *mspan //链表前向指针,用于将span链接起来 prev *mspan //链表前向指针,用于将span链接起来 startAddr uintptr // 起始地址,也即所管理页的地址 npages uintptr // 管理的页数 nelems uintptr // 块个数,也即有多少个块可供分配 allocBits *gcBits //分配位图,每一位代表一个块是否已分配 allocCount uint16 // 已分配块的个数 spanclass spanClass // class表中的class ID elemsize uintptr // class表中的对象大小,也即块大小 }cache 有了管理内存的基本单位span,还要有个数据结构来管理span,这个数据结构叫mcentral,各线程需要内存时从mcentral管理的span中申请内存,为了避免多线程申请内存时不断的加锁,Golang为每个线程分配了span的缓存,这个缓存即是cache。src/runtime/mcache.go:mcache 定义了cache的数据结构:type mcache struct { alloc [67*2]*mspan // 按class分组的mspan列表 }alloc为mspan的指针数组,数组大小为class总数的2倍。数组中每个元素代表了一种class类型的span列表,每种class类型都有两组span列表,第一组列表中所表示的对象中包含了指针,第二组列表中所表示的对象不含有指针,这么做是为了提高GC扫描性能,对于不包含指针的span列表,没必要去扫描。根据对象是否包含指针,将对象分为noscan和scan两类,其中noscan代表没有指针,而scan则代表有指针,需要GC进行扫描。mcache和span的对应关系如下图所示: chache在初始化时是没有任何span的,在使用过程中会动态的从central中获取并缓存下来,跟据使用情况,每种class的span个数也不相同。上图所示,class 0的span数比class1的要多,说明本线程中分配的小对象要多一些。central cache作为线程的私有资源为单个线程服务,而central则是全局资源,为多个线程服务,当某个线程内存不足时会向central申请,当某个线程释放内存时又会回收进central。src/runtime/mcentral.go:mcentral 定义了central数据结构:type mcentral struct { lock mutex //互斥锁 spanclass spanClass // span class ID nonempty mSpanList // non-empty 指还有空闲块的span列表 empty mSpanList // 指没有空闲块的span列表 nmalloc uint64 // 已累计分配的对象个数 }lock: 线程间互斥锁,防止多线程读写冲突spanclass : 每个mcentral管理着一组有相同class的span列表nonempty: 指还有内存可用的span列表empty: 指没有内存可用的span列表nmalloc: 指累计分配的对象个数线程从central获取span步骤如下:5.1 加锁5.2 从nonempty列表获取一个可用span,并将其从链表中删除5.3 将取出的span放入empty链表5.4 将span返回给线程5.5 解锁线程将该span缓存进cache线程将span归还步骤如下:5.1 加锁5.2 将span从empty列表删除5.3 将span加入noneempty列表5.4 解锁heap 从mcentral数据结构可见,每个mcentral对象只管理特定的class规格的span。事实上每种class都会对应一个mcentral,这个mcentral的集合存放于mheap数据结构中。src/runtime/mheap.go:mheap 定义了heap的数据结构:type mheap struct { lock mutex spans []*mspan bitmap uintptr //指向bitmap首地址,bitmap是从高地址向低地址增长的 arena_start uintptr //指示arena区首地址 arena_used uintptr //指示arena区已使用地址位置 central [67*2]struct { mcentral mcentral pad [sys.CacheLineSize - unsafe.Sizeof(mcentral{})%sys.CacheLineSize]byte } }lock: 互斥锁spans: 指向spans区域,用于映射span和page的关系bitmap:bitmap的起始地址arena_start: arena区域首地址arena_used: 当前arena已使用区域的最大地址central: 每种class对应的两个mcentral从数据结构可见,mheap管理着全部的内存,事实上Golang就是通过一个mheap类型的全局变量进行内存管理的。mheap内存管理示意图如下: 内存分配的过程针对待分配对象的大小不同有不同的分配逻辑:(0, 16B) 且不包含指针的对象: Tiny分配(0, 16B) 包含指针的对象:正常分配[16B, 32KB] : 正常分配(32KB, -) : 大对象分配其中Tiny分配和大对象分配都属于内存管理的优化范畴,这里暂时仅关注一般的分配方法。以申请size为n的内存为例,分配步骤如下:获取当前线程的私有缓存mcache跟据size计算出适合的class的ID从mcache的alloc[class]链表中查询可用的span如果mcache没有可用的span则从mcentral申请一个新的span加入mcache中如果mcentral中也没有可用的span则从mheap中申请一个新的span加入mcentral从该span中获取到空闲对象地址并返回{/collapse-item}{collapse-item label=" 6. 总结 " open} 每种内存分配器都有其独特的设计理念和优化策略。了解这些不同实现的原理不仅对深入理解语言和环境的内存管理有帮助,也对编写高效且资源友好的代码至关重要。本篇博客提供了一个概览,介绍了多种内存分配器的设计和实现。从经典的malloc到现代语言如GoLang的内存管理,我们看到了内存分配技术的演进和优化。希望这篇文章能为你在内存管理方面的深入学习提供一个坚实的起点。{/collapse-item}{/collapse}
The Art of Memory Allocation: Malloc, Slab, C++ STL, and GoLang Memory Allocation 在现代编程中,内存管理是一个核心且复杂的话题。本文将探讨不同语言和环境下内存分配器的实现,包括传统的malloc,Slab分配器,C++ STL内存分配器,以及GoLang的内存分配机制。我们的目标是理解这些内存分配器背后的设计思想和底层原理。今天在看到golang的内存配分机制,突然想到以前看过的一些内存分配的底层原理,正好可以一起整理下。{collapse}{collapse-item label="1. 内存分配器设计概念 " open} 内存分配器的设计首先考虑的是如何组织和管理空闲块。这涉及到空闲块的存放、分割和合并等操作。成功的内存管理不仅需要有效地分配和释放内存,还需要尽量减少内存碎片。空闲块的组织是个学问,操作系统中常见的空闲块组织的策略分为隐式空闲链表、显式空闲链表、分离的空闲链表三种,现在很多内存分配器中用的最多的还是分离空闲链表居多。空闲块组织方式策略隐式空闲链表空闲块是通过头部中的大小字段隐含地连接着,强制的系统对齐要求,分配器对块格式的选择会对分配器上的最小块大小有强制要求显示空闲链表新释放的块放置在链表的开始处,链表中的每个块的地址都小于它后继的地址分离的空闲链表维护多个空闲链表,其中每个链表中的块有大致相等的大小,将所有可能的块大小分成大小类,简单分离存储、分离适配、伙伴系统分离的空闲链表分配释放简单分离存储只分配释放,不分割合并分配时从相应空闲链表中选择第一块的全部,释放时直接将块插入到相应空闲链表的头部分离适配查找适当的空闲链表做首次适配,查找到一个合适的块,如果找到就可选的分割它,将剩余部分插入到适当的空闲链表中找不到合适的块,就搜索下一个更大的空闲链表,如果空闲链表中没有合适的块,那么就向操作系统中请求额外的堆内存,从这个新的堆内存中分配出一个块,剩余部分放置在适当的空闲链表中执行合并,将结果放置到相应的空闲链表伙伴系统每个大小类都是2的幂,请求块大小向上舍入到最接近2的幂,将一个内存块二分直至等于请求块大小,剩余的半块放置到相应的空闲链表中给定块地址和大小就可以知道伙伴的地址,不断合并空闲伙伴,遇到已分配伙伴就停止合并{/collapse-item}{collapse-item label="2. 经典的Malloc实现" open} 在C语言中,malloc()函数是动态内存分配的基石。这个函数通常使用glibc的ptmalloc2实现。然而,tcmalloc(来自Google)和jemalloc(来自Facebook)等现代分配器在性能和减少内存碎片方面有显著优势,尤其是在多线程环境下。malloc内存池的实现2.1 分配的内存大小小于512字节,则通过内存大小定位到small bins对应的index上,大小整除8为索引2.2 如果对应的bins上有空闲块,返回2.3 如果对应的bins上没有空闲块,则遍历unsorted list,查找合适大小的空闲块,找到则返回,未找到,将unsorted list中的块归类到small bins和large bins,index++,查找更大的链表,找到则返回,剩下的加入到unsorted list,否则使用top chunk2.4 如果还未找到空闲块,则会根据需要申请的内存大小来使用分配策略,内存小于128k使用brk,内存大于128k,使用mmap2.1如果分配内存大小大于512字节,定位到large bins对应的index上,跳到2.2free释放的chunk是否与top chunk相邻,相邻则合并释放的chunk是否与top chunk不相邻,插入到unsorted list{/collapse-item}{collapse-item label=" 3. Slab分配器" open} Slab分配器主要用于内核内存分配,其主要思想是缓存常用对象以减少初始化和销毁成本。Slab分配器通过维护一组预先分配的对象"slabs"来实现这一点,这大大加速了分配过程。slab分配器高效的解决了内碎和外碎的问题,解决外碎的主要方式是把所有的空闲物理页分组为11块链表,每块链表分别包含大小为1,2,4,8,16...1024个连续的物理页,每个页常规大小是4096(4k),页帧(物理页)的分配由伙伴系统进行解决内碎的方式是对于频繁地分配和释放的数据结构,会缓存它,对象析构仅是标记slab的数据结构如下 高速缓存组(链表),每一个高速缓存里面存储着对象的大小,3个slab链表,每个链表的节点是一个slab,每个slab包含了一个或多个物理页,每个物理页存储着高速缓冲对应的对象大小,每一个高速缓存有三种状态的full、partial、free的slab对象的链表{/collapse-item}{collapse-item label="4. C++ STL内存分配器 " open} C++标准模板库(STL)提供了一套灵活的内存分配器接口。STL内存分配器可以定制,支持不同类型的内存分配策略,这对于优化性能和内存使用非常有用。c++ stl内存分配器 new 调用operator new配置内存 调用对象构造函数构造对象内容 delete 调用对象析构函数 调用成员的operator delete释放内存空间分配器SGI标准的空间配置器 效率不佳,只是将c++的new,delete薄薄的包装了一层 allocate deallocateSGI特殊的空间配置器 将new和delete两个阶段的操作分开来 alloc::allocate(num) 为num个元素分配内存 alloc::deallocate(p, num) 回收p所指的“可容纳num个元素”的内存空间 ::construct(p, val) 将p所指的元素初始化为val ::destroy(p)/::destroy(first, last) 销毁p所指的元素/销毁迭代器所指的区间第一级配置器 alloc::allocate(num) 使用malloc分配内存,分配失败则改用oom_malloc, oom_malloc将不断调用客户端设置的内存不足例程,不断尝试释放、配置,如果客户端未设置该函数将抛出异常bad_alloc或利用exit(0)终止程序 alloc::deallocate(p, num) 直接使用free第二级配置器 次层配置,提升内存管理的效率,减小内存造成的内存碎片问题 分配:分配空间大小超过128bytes时,会使用第一级空间配置器,直接使用malloc relloc free,如果分配不成功则调用句柄释放一部分内存,如果还不能成功则抛出异常分配空间大小小于128bytes时,会使用第二级空间配置器,内存池和空闲链表 内存池管理:每次配置一大块内存,并且维护对应的16个空闲链表。16个空闲链表分别管理大小为8、16、24...120、128的数据块。数据结构 空闲链表节点实现,共用体的形式既可以存储下一个空闲节点又可以存储当前分配给客户使用的数据,当分配给客户时,将不需要记录到空闲链表中 内存池的开始位置、结束位置 alloc::allocate(num) 调用将用户申请的字节数扩大到8的倍数,,然后在自由链表中找到对应大小的子链表,找到有内存直接返回空闲链表头结点,空闲链表结点移动到下一个空闲结点,没有找到则调用refill()准备为freelist重新填充空间,新的空间将取自内存池(经由chunk_alloc完成),chunk_alloc缺省取得20个新节点,,根据内存池开始位置和结束位置来判断容量,但万一内存池空间不足,获得的节点可能小于20.如果块数不够20块,那尽可能的分配最多的块数给自由链表,并且更新每次申请的块数。如果一块都不够则把剩余的内存挂到自由链表,然后向系统heap申请空间,申请的大小为需求量的两倍,再加上一个随着申请次数递增的附加量,如果堆上malloc分配失败,chunk_alloc会从空闲链表中寻找更大的数据块分配给内存池,chunk_alloc递归调用,递归调用山穷水尽之后,则调用一级空间配置器,虽然也是malloc,不过一级空间配置器有out-of-memory处理机制,或许有机会释放一些空间,可以就成功 ,失败就抛出bad_alloc异常alloc::deallocate(p, num) 如果释放的内存大于128bytes时,调用free 如果释放的内存小于128bytes时,找到合适的自由链表插入{/collapse-item}{collapse-item label=" 5. GoLang内存分配实现" open} GoLang实现了自己的内存分配器,其原理与tcmalloc类似。它维护一块大的全局内存,每个线程(在GoLang中称为P)维护一块小的私有内存。当私有内存不足时,线程会从全局内存申请。内存结构: GoLang在启动时向系统申请一大块内存,这块内存被划分为spans、bitmap、arena三个部分。arena是堆区,用于分配应用所需内存,而spans和bitmap则用于管理arena区。Span的角色: Span是内存管理的基本单位,每个span可以包含一个或多个连续的页。为了满足小对象的分配,span中的一页可以进一步划分为更小的单元。对于大对象,可以通过多页span来实现。Class的分配: GoLang根据对象的大小划分了多个class,每个class代表一个固定大小的对象和每个span的大小。这种分类有助于优化内存分配效率和减少碎片。mcache和mcentral: GoLang为每个线程分配了span的缓存(mcache),这些缓存的资源来自于全局的mcentral。mcentral管理多个span供线程申请使用。内存分配过程: 当线程需要内存时,它会首先在mcache中寻找可用的span。如果mcache中没有可用的span,则从mcentral请求。如果mcentral也没有可用的span,则从全局的mheap中申请新的span。golang程序启动的时候会向系统申请内存如下 预申请的内存划分为spans、bitmap、arena三部分。其中arena即为所谓的堆区,应用中需要的内存从这里分配。其中spans和bitmap是为了管理arena区而存在的。arena的大小为512G,为了方便管理把arena区域划分成一个个的page,每个page为8KB,一共有512GB/8KB个页;spans区域存放span的指针,每个指针对应一个page,所以span区域的大小为(512GB/8KB)*指针大小8byte = 512Mbitmap区域大小也是通过arena计算出来,不过主要用于GC。span span是用于管理arena页的关键数据结构,每个span中包含1个或多个连续页,为了满足小对象分配,span中的一页会划分更小的粒度,而对于大对象比如超过页大小,则通过多页实现。 class 跟据对象大小,划分了一系列class,每个class都代表一个固定大小的对象,以及每个span的大小// class bytes/obj bytes/span objects waste bytes // 1 8 8192 1024 0 // 2 16 8192 512 0 // 3 32 8192 256 0 // 4 48 8192 170 32 // .... // 66 32768 32768 1 0上表中每列含义如下:class: class ID,每个span结构中都有一个class ID, 表示该span可处理的对象类型bytes/obj:该class代表对象的字节数bytes/span:每个span占用堆的字节数,也即页数*页大小objects: 每个span可分配的对象个数,也即(bytes/spans)/(bytes/obj)waste bytes: 每个span产生的内存碎片,也即(bytes/spans)%(bytes/obj)上表可见最大的对象是32K大小,超过32K大小的由特殊的class表示,该class ID为0,每个class只包含一个对象。src/runtime/mheap.go:mspan 定义了其数据结构:type mspan struct { next *mspan //链表前向指针,用于将span链接起来 prev *mspan //链表前向指针,用于将span链接起来 startAddr uintptr // 起始地址,也即所管理页的地址 npages uintptr // 管理的页数 nelems uintptr // 块个数,也即有多少个块可供分配 allocBits *gcBits //分配位图,每一位代表一个块是否已分配 allocCount uint16 // 已分配块的个数 spanclass spanClass // class表中的class ID elemsize uintptr // class表中的对象大小,也即块大小 }cache 有了管理内存的基本单位span,还要有个数据结构来管理span,这个数据结构叫mcentral,各线程需要内存时从mcentral管理的span中申请内存,为了避免多线程申请内存时不断的加锁,Golang为每个线程分配了span的缓存,这个缓存即是cache。src/runtime/mcache.go:mcache 定义了cache的数据结构:type mcache struct { alloc [67*2]*mspan // 按class分组的mspan列表 }alloc为mspan的指针数组,数组大小为class总数的2倍。数组中每个元素代表了一种class类型的span列表,每种class类型都有两组span列表,第一组列表中所表示的对象中包含了指针,第二组列表中所表示的对象不含有指针,这么做是为了提高GC扫描性能,对于不包含指针的span列表,没必要去扫描。根据对象是否包含指针,将对象分为noscan和scan两类,其中noscan代表没有指针,而scan则代表有指针,需要GC进行扫描。mcache和span的对应关系如下图所示: chache在初始化时是没有任何span的,在使用过程中会动态的从central中获取并缓存下来,跟据使用情况,每种class的span个数也不相同。上图所示,class 0的span数比class1的要多,说明本线程中分配的小对象要多一些。central cache作为线程的私有资源为单个线程服务,而central则是全局资源,为多个线程服务,当某个线程内存不足时会向central申请,当某个线程释放内存时又会回收进central。src/runtime/mcentral.go:mcentral 定义了central数据结构:type mcentral struct { lock mutex //互斥锁 spanclass spanClass // span class ID nonempty mSpanList // non-empty 指还有空闲块的span列表 empty mSpanList // 指没有空闲块的span列表 nmalloc uint64 // 已累计分配的对象个数 }lock: 线程间互斥锁,防止多线程读写冲突spanclass : 每个mcentral管理着一组有相同class的span列表nonempty: 指还有内存可用的span列表empty: 指没有内存可用的span列表nmalloc: 指累计分配的对象个数线程从central获取span步骤如下:5.1 加锁5.2 从nonempty列表获取一个可用span,并将其从链表中删除5.3 将取出的span放入empty链表5.4 将span返回给线程5.5 解锁线程将该span缓存进cache线程将span归还步骤如下:5.1 加锁5.2 将span从empty列表删除5.3 将span加入noneempty列表5.4 解锁heap 从mcentral数据结构可见,每个mcentral对象只管理特定的class规格的span。事实上每种class都会对应一个mcentral,这个mcentral的集合存放于mheap数据结构中。src/runtime/mheap.go:mheap 定义了heap的数据结构:type mheap struct { lock mutex spans []*mspan bitmap uintptr //指向bitmap首地址,bitmap是从高地址向低地址增长的 arena_start uintptr //指示arena区首地址 arena_used uintptr //指示arena区已使用地址位置 central [67*2]struct { mcentral mcentral pad [sys.CacheLineSize - unsafe.Sizeof(mcentral{})%sys.CacheLineSize]byte } }lock: 互斥锁spans: 指向spans区域,用于映射span和page的关系bitmap:bitmap的起始地址arena_start: arena区域首地址arena_used: 当前arena已使用区域的最大地址central: 每种class对应的两个mcentral从数据结构可见,mheap管理着全部的内存,事实上Golang就是通过一个mheap类型的全局变量进行内存管理的。mheap内存管理示意图如下: 内存分配的过程针对待分配对象的大小不同有不同的分配逻辑:(0, 16B) 且不包含指针的对象: Tiny分配(0, 16B) 包含指针的对象:正常分配[16B, 32KB] : 正常分配(32KB, -) : 大对象分配其中Tiny分配和大对象分配都属于内存管理的优化范畴,这里暂时仅关注一般的分配方法。以申请size为n的内存为例,分配步骤如下:获取当前线程的私有缓存mcache跟据size计算出适合的class的ID从mcache的alloc[class]链表中查询可用的span如果mcache没有可用的span则从mcentral申请一个新的span加入mcache中如果mcentral中也没有可用的span则从mheap中申请一个新的span加入mcentral从该span中获取到空闲对象地址并返回{/collapse-item}{collapse-item label=" 6. 总结 " open} 每种内存分配器都有其独特的设计理念和优化策略。了解这些不同实现的原理不仅对深入理解语言和环境的内存管理有帮助,也对编写高效且资源友好的代码至关重要。本篇博客提供了一个概览,介绍了多种内存分配器的设计和实现。从经典的malloc到现代语言如GoLang的内存管理,我们看到了内存分配技术的演进和优化。希望这篇文章能为你在内存管理方面的深入学习提供一个坚实的起点。{/collapse-item}{/collapse} -
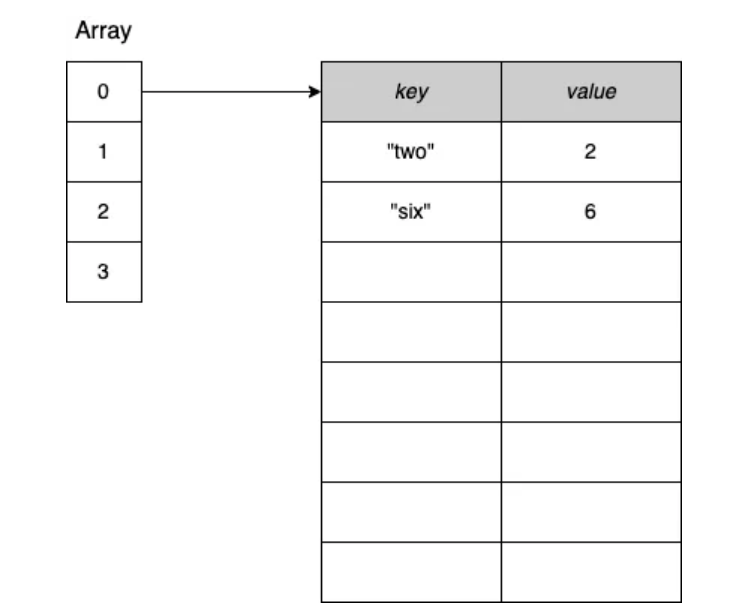
![Maps and Memory Leaks in Go]() Maps and Memory Leaks in Go 在使用 Go 中的 map 时,我们需要了解 map 如何增长和收缩的一些重要特性。让我们深入了解这一点,以防止可能导致内存泄漏的问题。首先,为了查看这个问题的具体示例,让我们设计一个场景,我们将在其中使用以下的 map:m := make(map[int][128]byte)其中 m 的每个值都是一个包含 128 字节的数组。我们将执行以下操作:分配一个空的 map。添加 100 万个元素。删除所有元素,并运行垃圾回收(GC)。在每个步骤之后,我们想打印堆的大小(使用 printAlloc 实用函数)。这可以展示这个例子在内存方面的行为:func main() { n := 1_000_000 m := make(map[int][128]byte) printAlloc() for i := 0; i < n; i++ { // 添加 100 万个元素 m[i] = [128]byte{} } printAlloc() for i := 0; i < n; i++ { // 删除 100 万个元素 delete(m, i) } runtime.GC() // 手动触发 GC printAlloc() runtime.KeepAlive(m) // 保持对 m 的引用,以防 map 被收集 } func printAlloc() { var m runtime.MemStats runtime.ReadMemStats(&m) fmt.Printf("%d MB\n", m.Alloc/(1024*1024)) }我们分配了一个空的 map,添加了 100 万个元素,删除了 100 万个元素,然后运行了 GC。我们还确保使用 runtime.KeepAlive 保持对 map 的引用,以便 map 也不会被回收。让我们运行这个例子:0 MB <-- 分配 m 之后 461 MB <-- 添加 100 万个元素之后 293 MB <-- 删除 100 万个元素之后我们可以观察到什么?最初,堆的大小很小。然后,在将 100 万个元素添加到 map 后,堆的大小显著增长。但是,如果我们期望在删除所有元素后堆的大小会减小,这不是 Go 中 map 的工作方式。最终,即使 GC 已经收集了所有元素,堆的大小仍然是 293 MB。因此,内存减少了,但并非我们可能期望的那样。这是为什么呢?我们需要深入了解 Go 中的 map 是如何工作的。在 Go 中,map 提供了一个无序的键值对集合,其中所有键都是唯一的。在 Go 中,map 基于哈希表数据结构:一个数组,其中每个元素是指向键值对桶的指针,如图 1 所示。 图 1:哈希表示例,重点关注桶 0。每个桶都是一个固定大小的数组,有八个元素。在向已满的桶(桶溢出)插入元素的情况下,Go 会创建另一个包含八个元素的桶,并将前一个桶链接到它上面。图 2 展示了一个示例:图 2:在桶溢出的情况下,Go 分配一个新的桶,并将前一个桶链接到它上面。在底层,Go 的 map 是一个指向 runtime.hmap 结构体的指针。该结构体包含多个字段,包括 B 字段,给出了 map 中桶的数量:type hmap struct { B uint8 // 桶的数量的 log_2 // (可以容纳 loadFactor * 2^B 个项) // ... }在添加了 100 万个元素后,B 的值等于 18,这意味着有 2¹⁸ = 262,144 个桶。当我们删除了 100 万个元素后,B 的值是多少呢?仍然是 18。因此,该 map 仍然包含相同数量的桶。原因是 map 中的桶数不能减少。因此,从 map 中删除元素不会影响现有桶的数量;它只是将桶中的槽清零。一个 map 只能增长并拥有更多的桶;它永远不会收缩。在上面的例子中,我们从 461 MB 减少到 293 MB,因为元素已经被收集,但运行 GC 并没有影响 map 本身。即使额外桶的数量(由于溢出而创建的桶)也保持不变。让我们退后一步,讨论 map 不能收缩的事实何时可能成为问题。想象一下,使用 mapintbyte 构建一个缓存。这个 map 持有每个客户 ID(int)的 128 字节序列。现在,假设我们想保存最后 1,000 位客户的数据。map 的大小将保持不变,因此我们不必担心 map 不能收缩的事实。然而,假设我们想要存储一小时的数据。同时,我们的公司决定在黑色星期五推出一个大促销:在一个小时内,我们可能有数百万与我们系统连接的客户。但在黑色星期五几天后,我们的 map 将包含与高峰时期相同数量的桶。这就解释了为什么在这种情况下我们可能会遇到内存消耗高,而在很大程度上不会减少的情况。如果我们不想手动重新启动服务以清理 map 消耗的内存量,有什么解决方案呢?一个解决方案可能是定期重新创建当前 map 的副本。例如,每小时,我们可以构建一个新的 map,复制所有元素,并释放先前的 map。这个选项的主要缺点是,在复制之后直到下一次垃圾回收之前,我们可能会在短时间内消耗两倍的当前内存。另一个解决方案是将 map 类型更改为存储数组指针:map[int]*[128]byte。虽然这并不能解决 map 拥有大量桶的问题;但是,每个桶条目将为值保留指针的大小,而不是 128 字节(在 64 位系统上为 8 字节,在 32 位系统上为 4 字节)。回到原始场景,让我们比较每种 map 类型在每个步骤后的内存消耗。以下表格显示了比较。stepmapintbytemap[int]*[128]byte分配一个空的map0 MB0 MB添加 100 万个元素461 MB182 MB删除所有元素并运行GC293 MB38 MB注意:如果键或值超过 128 字节,Go 将不会直接将其存储在 map 桶中。相反,Go 会存储一个指针来引用键或值。正如我们所见,向 map 添加 n 个元素,然后删除所有元素意味着保持相同数量的桶在内存中。因此,我们必须记住,由于 Go map 只能增长,因此它的内存消耗也会增加。没有自动的策略来收缩它。如果这导致内存消耗过高,我们可以尝试不同的选项,如强制 Go 重新创建 map 或使用指针来检查是否可以进行优化。
Maps and Memory Leaks in Go 在使用 Go 中的 map 时,我们需要了解 map 如何增长和收缩的一些重要特性。让我们深入了解这一点,以防止可能导致内存泄漏的问题。首先,为了查看这个问题的具体示例,让我们设计一个场景,我们将在其中使用以下的 map:m := make(map[int][128]byte)其中 m 的每个值都是一个包含 128 字节的数组。我们将执行以下操作:分配一个空的 map。添加 100 万个元素。删除所有元素,并运行垃圾回收(GC)。在每个步骤之后,我们想打印堆的大小(使用 printAlloc 实用函数)。这可以展示这个例子在内存方面的行为:func main() { n := 1_000_000 m := make(map[int][128]byte) printAlloc() for i := 0; i < n; i++ { // 添加 100 万个元素 m[i] = [128]byte{} } printAlloc() for i := 0; i < n; i++ { // 删除 100 万个元素 delete(m, i) } runtime.GC() // 手动触发 GC printAlloc() runtime.KeepAlive(m) // 保持对 m 的引用,以防 map 被收集 } func printAlloc() { var m runtime.MemStats runtime.ReadMemStats(&m) fmt.Printf("%d MB\n", m.Alloc/(1024*1024)) }我们分配了一个空的 map,添加了 100 万个元素,删除了 100 万个元素,然后运行了 GC。我们还确保使用 runtime.KeepAlive 保持对 map 的引用,以便 map 也不会被回收。让我们运行这个例子:0 MB <-- 分配 m 之后 461 MB <-- 添加 100 万个元素之后 293 MB <-- 删除 100 万个元素之后我们可以观察到什么?最初,堆的大小很小。然后,在将 100 万个元素添加到 map 后,堆的大小显著增长。但是,如果我们期望在删除所有元素后堆的大小会减小,这不是 Go 中 map 的工作方式。最终,即使 GC 已经收集了所有元素,堆的大小仍然是 293 MB。因此,内存减少了,但并非我们可能期望的那样。这是为什么呢?我们需要深入了解 Go 中的 map 是如何工作的。在 Go 中,map 提供了一个无序的键值对集合,其中所有键都是唯一的。在 Go 中,map 基于哈希表数据结构:一个数组,其中每个元素是指向键值对桶的指针,如图 1 所示。 图 1:哈希表示例,重点关注桶 0。每个桶都是一个固定大小的数组,有八个元素。在向已满的桶(桶溢出)插入元素的情况下,Go 会创建另一个包含八个元素的桶,并将前一个桶链接到它上面。图 2 展示了一个示例:图 2:在桶溢出的情况下,Go 分配一个新的桶,并将前一个桶链接到它上面。在底层,Go 的 map 是一个指向 runtime.hmap 结构体的指针。该结构体包含多个字段,包括 B 字段,给出了 map 中桶的数量:type hmap struct { B uint8 // 桶的数量的 log_2 // (可以容纳 loadFactor * 2^B 个项) // ... }在添加了 100 万个元素后,B 的值等于 18,这意味着有 2¹⁸ = 262,144 个桶。当我们删除了 100 万个元素后,B 的值是多少呢?仍然是 18。因此,该 map 仍然包含相同数量的桶。原因是 map 中的桶数不能减少。因此,从 map 中删除元素不会影响现有桶的数量;它只是将桶中的槽清零。一个 map 只能增长并拥有更多的桶;它永远不会收缩。在上面的例子中,我们从 461 MB 减少到 293 MB,因为元素已经被收集,但运行 GC 并没有影响 map 本身。即使额外桶的数量(由于溢出而创建的桶)也保持不变。让我们退后一步,讨论 map 不能收缩的事实何时可能成为问题。想象一下,使用 mapintbyte 构建一个缓存。这个 map 持有每个客户 ID(int)的 128 字节序列。现在,假设我们想保存最后 1,000 位客户的数据。map 的大小将保持不变,因此我们不必担心 map 不能收缩的事实。然而,假设我们想要存储一小时的数据。同时,我们的公司决定在黑色星期五推出一个大促销:在一个小时内,我们可能有数百万与我们系统连接的客户。但在黑色星期五几天后,我们的 map 将包含与高峰时期相同数量的桶。这就解释了为什么在这种情况下我们可能会遇到内存消耗高,而在很大程度上不会减少的情况。如果我们不想手动重新启动服务以清理 map 消耗的内存量,有什么解决方案呢?一个解决方案可能是定期重新创建当前 map 的副本。例如,每小时,我们可以构建一个新的 map,复制所有元素,并释放先前的 map。这个选项的主要缺点是,在复制之后直到下一次垃圾回收之前,我们可能会在短时间内消耗两倍的当前内存。另一个解决方案是将 map 类型更改为存储数组指针:map[int]*[128]byte。虽然这并不能解决 map 拥有大量桶的问题;但是,每个桶条目将为值保留指针的大小,而不是 128 字节(在 64 位系统上为 8 字节,在 32 位系统上为 4 字节)。回到原始场景,让我们比较每种 map 类型在每个步骤后的内存消耗。以下表格显示了比较。stepmapintbytemap[int]*[128]byte分配一个空的map0 MB0 MB添加 100 万个元素461 MB182 MB删除所有元素并运行GC293 MB38 MB注意:如果键或值超过 128 字节,Go 将不会直接将其存储在 map 桶中。相反,Go 会存储一个指针来引用键或值。正如我们所见,向 map 添加 n 个元素,然后删除所有元素意味着保持相同数量的桶在内存中。因此,我们必须记住,由于 Go map 只能增长,因此它的内存消耗也会增加。没有自动的策略来收缩它。如果这导致内存消耗过高,我们可以尝试不同的选项,如强制 Go 重新创建 map 或使用指针来检查是否可以进行优化。 -
![Golang Design Patterns]() Golang Design Patterns {collapse}{collapse-item label="Decorator Pattern" open} 1.定义装饰器模式是一种结构型设计模式,允许你通过将对象放入包含行为的特殊封装对象中来为原对象绑定新的行为。2.应用这是一个计算Π的函数func Pi(n int) float64 { ch := make(chan float64) for k := 0; k <= n; k++ { go func(ch chan float64, k float64) { ch <- 4 * math.Pow(-1, k) / (2*k + 1) }(ch, float64(k)) } result := 0.0 for k := 0; k <= n; k++ { result += <-ch } return result }现在如果需要在这个求Π的程序上增加一个功能,计算出求Π耗费的时间并将结果通过log对象打印出来,可以封装一个函数来增加这个功能,而不去破坏原来函数的结构type piFunc func(int) float64 // logger(cache(Pi(n))) func wraplogger(fun piFunc, logger *log.Logger) piFunc { return func(n int) float64 { fn := func(n int) (result float64) { defer func(t time.Time) { logger.Printf("took=%v, n=%v, result=%v", time.Since(t), n, result) }(time.Now()) return fun(n) } return fn(n) } }写一个测试例子看下效果func main() { g := wraplogger(pi, log.New(os.Stdout, "Test ", 1)) g(100000) g(20000) }如果现在需要再增加一个缓存的功能,计算过的结果存起来,继续封装一个函数扩充pi的功能// cache(logger(Pi(n))) func wrapcache(fun piFunc, cache *sync.Map) piFunc { return func(n int) float64 { fn := func(n int) float64 { key := fmt.Sprintf("n=%d", n) val, ok := cache.Load(key) if ok { return val.(float64) } result := fun(n) cache.Store(key, result) return result } return fn(n) } }写个测试例子测试下func main() { f := wrapcache(Pi, &sync.Map{}) g := wraplogger(f, log.New(os.Stdout, "Test ", 1)) g(100000) g(20000) g(100000) }如果现在不需要计算Π,而是对整数取半操作同时增加缓存,这个时候只需将wrapcache函数参数求Π函数换成取半函数即可func divide(n int) float64 { return float64(n / 2) } func main() { f := wrapcache(divide, &sync.Map{}) g := wraplogger(f, log.New(os.Stdout, "Divide ", 1)) g(10000) g(2000) g(10) g(10000) }3.优缺点优点缺点无需创建新子类即可扩展对象的行为在封装器栈中删除特定封装器比较困难可以在运行时添加或删除对象的功能实现行为不受装饰栈顺序影响的装饰比较困难可以用多个装饰封装对象来组合几种行为各层的初始化配置代码看上去可能会很糟糕单一职责原则,可以将实现了许多不同行为的一个大类拆分为多个较小的类 {/collapse-item}{collapse-item label="Generator And Observer Pattern" open}1.定义生成器模式是一种创建型设计模式,使你能够分步骤创建复杂对象.该模式允许你使用相同的创建代码生成不同类型和形式的对象观察者模式是一种行为设计模式,允许你定义一种订阅机制, 可在对象事件发生时通知多个 “观察” 该对象的其他对象2.应用生成器模式生成0-n的斐波那契数列package main import "fmt" func fib(n int) chan int { out := make(chan int) go func() { defer close(out) for i, j := 0, 1; i < n; i, j = i+j, i { out <- i } }() return out } // 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, ... func main() { for x := range fib(10000000) { fmt.Println(x) } }观察者模式观察者模式主要是两个角色,一个发布者,一个订阅者先定义发布者的接口发布者拥有增加/删除订阅者、通知订阅者的功能type Subject interface { AddListener(Observer) RemoveListener(Observer) Notify(Event) }订阅者的接口订阅者就是所说的观察者拥有订阅时间发生时被通知的接口Observer interface { NotifyCallback(Event) }以下是通过实现发布者和订阅接口,实现的通知观察者斐波那契结果的功能package main package main import ( "fmt" "sync" "time" ) type ( Event struct { data int } Observer interface { NotifyCallback(Event) } Subject interface { AddListener(Observer) RemoveListener(Observer) Notify(Event) } eventObserver struct { id int time time.Time } eventSubject struct { observers sync.Map } ) func (e *eventObserver) NotifyCallback(event Event) { fmt.Printf("Observer: %d Recieved: %d after %v\n", e.id, event.data, time.Since(e.time)) } func (s *eventSubject) AddListener(obs Observer) { s.observers.Store(obs, struct{}{}) } func (s *eventSubject) RemoveListener(obs Observer) { s.observers.Delete(obs) } func (s *eventSubject) Notify(event Event) { s.observers.Range(func(key interface{}, value interface{}) bool { if key == nil || value == nil { return false } key.(Observer).NotifyCallback(event) return true }) } func fib(n int) chan int { out := make(chan int) go func() { defer close(out) for i, j := 0, 1; i < n; i, j = i+j, i { out <- i } }() return out } // 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, ... func main() { n := eventSubject{ observers: sync.Map{}, } t := time.Now() var obs1 = eventObserver{id: 1, time: t} var obs2 = eventObserver{id: 2, time: t} n.AddListener(&obs1) n.AddListener(&obs2) go func() { select { case <-time.After(time.Millisecond * 10): n.RemoveListener(&obs1) } }() for x := range fib(100000) { n.Notify(Event{data: x}) } }3.优缺点生成器模式优点缺点可以分步创建对象,暂缓创建步骤或递归运行创建步骤由于该模式需要新增多个类,因此代码整体复杂程度会有所增加生成不同形式的产品时,可以复用相同的制造代码 单一职责原则,可以将复杂构造代码从产品的业务逻辑中分离出来 观察者模式优点缺点开闭原则,无需修改发布者代码就能引入新的订阅者类(如果是发布者接口则可轻松引入发布者类)订阅者的通知顺序是随机的可以在运行时建立对象之间的联系 {/collapse-item}{collapse-item label="Factory And Abstract Factory Pattern" open}1.定义工厂方法模式是一种创建型设计模式, 其在父类中提供一个创建对象的方法, 允许子类决定实例化对象的类型抽象工厂模式是一种创建型设计模式, 它能创建一系列相关的对象, 而无需指定其具体类。2.应用工厂模式当业务需要存储时,底层存储的方式有很多种实现,上层并不需要关心底层存储方式,故只需提供一个存储和获取数据的接口就行,就用到了工厂模式type ( mongoDB struct { database map[string]string } sqlite struct { database map[string]string } Database interface { GetData(string) string PutData(string, string) } ) func (mdb mongoDB) GetData(query string) string { if _, ok := mdb.database[query]; !ok { return "" } fmt.Println("MongoDB") return mdb.database[query] } func (sql sqlite) GetData(query string) string { if _, ok := sql.database[query]; !ok { return "" } fmt.Println("Sqlite") return sql.database[query] } func (mdb mongoDB) PutData(query string, data string) { mdb.database[query] = data } func (sql sqlite) PutData(query string, data string) { sql.database[query] = data } func DatabaseFactory(env string) interface{} { switch env { case "production": return mongoDB{ database: make(map[string]string), } case "development": return sqlite{ database: make(map[string]string), } default: return nil } }抽象工厂模式如果底层存储除了数据库存储,还需要扩展成文件存储的功能,文件存储只关心创建文件和获取文件,这个时候就需要再将工厂抽象一层,让他可以拥有不同类型的工厂的功能type ( mongoDB struct { database map[string]string } sqlite struct { database map[string]string } file struct { name string content string } ntfs struct { files map[string]file } ext4 struct { files map[string]file } FileSystem interface { CreateFile(string) FindFile(string) file } Database interface { GetData(string) string PutData(string, string) } Factory func(string) interface{} ) func (mdb mongoDB) GetData(query string) string { if _, ok := mdb.database[query]; !ok { return "" } fmt.Println("MongoDB") return mdb.database[query] } func (sql sqlite) GetData(query string) string { if _, ok := sql.database[query]; !ok { return "" } fmt.Println("Sqlite") return sql.database[query] } func (mdb mongoDB) PutData(query string, data string) { mdb.database[query] = data } func (sql sqlite) PutData(query string, data string) { sql.database[query] = data } func (ntfs ntfs) CreateFile(path string) { file := file{content: "NTFS file", name: path} ntfs.files[path] = file fmt.Println("NTFS") } func (ext ext4) CreateFile(path string) { file := file{content: "EXT4 file", name: path} ext.files[path] = file fmt.Println("EXT4") } func (ntfs ntfs) FindFile(path string) file { if _, ok := ntfs.files[path]; !ok { return file{} } return ntfs.files[path] } func (ext ext4) FindFile(path string) file { if _, ok := ext.files[path]; !ok { return file{} } return ext.files[path] } func FilesystemFactory(env string) interface{} { switch env { case "production": return ntfs{ files: make(map[string]file), } case "development": return ext4{ files: make(map[string]file), } default: return nil } } func DatabaseFactory(env string) interface{} { switch env { case "production": return mongoDB{ database: make(map[string]string), } case "development": return sqlite{ database: make(map[string]string), } default: return nil } } func AbstractFactory(fact string) Factory { switch fact { case "database": return DatabaseFactory case "filesystem": return FilesystemFactory default: return nil } }3.优缺点工厂模式优点缺点可以避免创建者和具体产品之间的紧密耦合应用工厂方法模式需要引入许多新的子类, 代码可能会因此变得更复杂。 最好的情况是将该模式引入创建者类的现有层次结构中单一职责原则,你可以将产品创建代码放在程序的单一位置,从而使得代码更容易维护 开闭原则,无需更改现有客户端代码,你就可以在程序中引入新的产品类型 抽象工厂优点缺点可以确保同一工厂生成的产品相互匹配由于采用该模式需要向应用中引入众多接口和类,代码可能会比之前更加复杂可以避免客户端和具体产品代码的耦合 单一职责原则,你可以将产品生成代码抽取到同一位置,使得代码易于维护 开闭原则,向应用程序中引入新产品变体时,你无需修改客户端代码 {/collapse-item}{/collapse}
Golang Design Patterns {collapse}{collapse-item label="Decorator Pattern" open} 1.定义装饰器模式是一种结构型设计模式,允许你通过将对象放入包含行为的特殊封装对象中来为原对象绑定新的行为。2.应用这是一个计算Π的函数func Pi(n int) float64 { ch := make(chan float64) for k := 0; k <= n; k++ { go func(ch chan float64, k float64) { ch <- 4 * math.Pow(-1, k) / (2*k + 1) }(ch, float64(k)) } result := 0.0 for k := 0; k <= n; k++ { result += <-ch } return result }现在如果需要在这个求Π的程序上增加一个功能,计算出求Π耗费的时间并将结果通过log对象打印出来,可以封装一个函数来增加这个功能,而不去破坏原来函数的结构type piFunc func(int) float64 // logger(cache(Pi(n))) func wraplogger(fun piFunc, logger *log.Logger) piFunc { return func(n int) float64 { fn := func(n int) (result float64) { defer func(t time.Time) { logger.Printf("took=%v, n=%v, result=%v", time.Since(t), n, result) }(time.Now()) return fun(n) } return fn(n) } }写一个测试例子看下效果func main() { g := wraplogger(pi, log.New(os.Stdout, "Test ", 1)) g(100000) g(20000) }如果现在需要再增加一个缓存的功能,计算过的结果存起来,继续封装一个函数扩充pi的功能// cache(logger(Pi(n))) func wrapcache(fun piFunc, cache *sync.Map) piFunc { return func(n int) float64 { fn := func(n int) float64 { key := fmt.Sprintf("n=%d", n) val, ok := cache.Load(key) if ok { return val.(float64) } result := fun(n) cache.Store(key, result) return result } return fn(n) } }写个测试例子测试下func main() { f := wrapcache(Pi, &sync.Map{}) g := wraplogger(f, log.New(os.Stdout, "Test ", 1)) g(100000) g(20000) g(100000) }如果现在不需要计算Π,而是对整数取半操作同时增加缓存,这个时候只需将wrapcache函数参数求Π函数换成取半函数即可func divide(n int) float64 { return float64(n / 2) } func main() { f := wrapcache(divide, &sync.Map{}) g := wraplogger(f, log.New(os.Stdout, "Divide ", 1)) g(10000) g(2000) g(10) g(10000) }3.优缺点优点缺点无需创建新子类即可扩展对象的行为在封装器栈中删除特定封装器比较困难可以在运行时添加或删除对象的功能实现行为不受装饰栈顺序影响的装饰比较困难可以用多个装饰封装对象来组合几种行为各层的初始化配置代码看上去可能会很糟糕单一职责原则,可以将实现了许多不同行为的一个大类拆分为多个较小的类 {/collapse-item}{collapse-item label="Generator And Observer Pattern" open}1.定义生成器模式是一种创建型设计模式,使你能够分步骤创建复杂对象.该模式允许你使用相同的创建代码生成不同类型和形式的对象观察者模式是一种行为设计模式,允许你定义一种订阅机制, 可在对象事件发生时通知多个 “观察” 该对象的其他对象2.应用生成器模式生成0-n的斐波那契数列package main import "fmt" func fib(n int) chan int { out := make(chan int) go func() { defer close(out) for i, j := 0, 1; i < n; i, j = i+j, i { out <- i } }() return out } // 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, ... func main() { for x := range fib(10000000) { fmt.Println(x) } }观察者模式观察者模式主要是两个角色,一个发布者,一个订阅者先定义发布者的接口发布者拥有增加/删除订阅者、通知订阅者的功能type Subject interface { AddListener(Observer) RemoveListener(Observer) Notify(Event) }订阅者的接口订阅者就是所说的观察者拥有订阅时间发生时被通知的接口Observer interface { NotifyCallback(Event) }以下是通过实现发布者和订阅接口,实现的通知观察者斐波那契结果的功能package main package main import ( "fmt" "sync" "time" ) type ( Event struct { data int } Observer interface { NotifyCallback(Event) } Subject interface { AddListener(Observer) RemoveListener(Observer) Notify(Event) } eventObserver struct { id int time time.Time } eventSubject struct { observers sync.Map } ) func (e *eventObserver) NotifyCallback(event Event) { fmt.Printf("Observer: %d Recieved: %d after %v\n", e.id, event.data, time.Since(e.time)) } func (s *eventSubject) AddListener(obs Observer) { s.observers.Store(obs, struct{}{}) } func (s *eventSubject) RemoveListener(obs Observer) { s.observers.Delete(obs) } func (s *eventSubject) Notify(event Event) { s.observers.Range(func(key interface{}, value interface{}) bool { if key == nil || value == nil { return false } key.(Observer).NotifyCallback(event) return true }) } func fib(n int) chan int { out := make(chan int) go func() { defer close(out) for i, j := 0, 1; i < n; i, j = i+j, i { out <- i } }() return out } // 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, ... func main() { n := eventSubject{ observers: sync.Map{}, } t := time.Now() var obs1 = eventObserver{id: 1, time: t} var obs2 = eventObserver{id: 2, time: t} n.AddListener(&obs1) n.AddListener(&obs2) go func() { select { case <-time.After(time.Millisecond * 10): n.RemoveListener(&obs1) } }() for x := range fib(100000) { n.Notify(Event{data: x}) } }3.优缺点生成器模式优点缺点可以分步创建对象,暂缓创建步骤或递归运行创建步骤由于该模式需要新增多个类,因此代码整体复杂程度会有所增加生成不同形式的产品时,可以复用相同的制造代码 单一职责原则,可以将复杂构造代码从产品的业务逻辑中分离出来 观察者模式优点缺点开闭原则,无需修改发布者代码就能引入新的订阅者类(如果是发布者接口则可轻松引入发布者类)订阅者的通知顺序是随机的可以在运行时建立对象之间的联系 {/collapse-item}{collapse-item label="Factory And Abstract Factory Pattern" open}1.定义工厂方法模式是一种创建型设计模式, 其在父类中提供一个创建对象的方法, 允许子类决定实例化对象的类型抽象工厂模式是一种创建型设计模式, 它能创建一系列相关的对象, 而无需指定其具体类。2.应用工厂模式当业务需要存储时,底层存储的方式有很多种实现,上层并不需要关心底层存储方式,故只需提供一个存储和获取数据的接口就行,就用到了工厂模式type ( mongoDB struct { database map[string]string } sqlite struct { database map[string]string } Database interface { GetData(string) string PutData(string, string) } ) func (mdb mongoDB) GetData(query string) string { if _, ok := mdb.database[query]; !ok { return "" } fmt.Println("MongoDB") return mdb.database[query] } func (sql sqlite) GetData(query string) string { if _, ok := sql.database[query]; !ok { return "" } fmt.Println("Sqlite") return sql.database[query] } func (mdb mongoDB) PutData(query string, data string) { mdb.database[query] = data } func (sql sqlite) PutData(query string, data string) { sql.database[query] = data } func DatabaseFactory(env string) interface{} { switch env { case "production": return mongoDB{ database: make(map[string]string), } case "development": return sqlite{ database: make(map[string]string), } default: return nil } }抽象工厂模式如果底层存储除了数据库存储,还需要扩展成文件存储的功能,文件存储只关心创建文件和获取文件,这个时候就需要再将工厂抽象一层,让他可以拥有不同类型的工厂的功能type ( mongoDB struct { database map[string]string } sqlite struct { database map[string]string } file struct { name string content string } ntfs struct { files map[string]file } ext4 struct { files map[string]file } FileSystem interface { CreateFile(string) FindFile(string) file } Database interface { GetData(string) string PutData(string, string) } Factory func(string) interface{} ) func (mdb mongoDB) GetData(query string) string { if _, ok := mdb.database[query]; !ok { return "" } fmt.Println("MongoDB") return mdb.database[query] } func (sql sqlite) GetData(query string) string { if _, ok := sql.database[query]; !ok { return "" } fmt.Println("Sqlite") return sql.database[query] } func (mdb mongoDB) PutData(query string, data string) { mdb.database[query] = data } func (sql sqlite) PutData(query string, data string) { sql.database[query] = data } func (ntfs ntfs) CreateFile(path string) { file := file{content: "NTFS file", name: path} ntfs.files[path] = file fmt.Println("NTFS") } func (ext ext4) CreateFile(path string) { file := file{content: "EXT4 file", name: path} ext.files[path] = file fmt.Println("EXT4") } func (ntfs ntfs) FindFile(path string) file { if _, ok := ntfs.files[path]; !ok { return file{} } return ntfs.files[path] } func (ext ext4) FindFile(path string) file { if _, ok := ext.files[path]; !ok { return file{} } return ext.files[path] } func FilesystemFactory(env string) interface{} { switch env { case "production": return ntfs{ files: make(map[string]file), } case "development": return ext4{ files: make(map[string]file), } default: return nil } } func DatabaseFactory(env string) interface{} { switch env { case "production": return mongoDB{ database: make(map[string]string), } case "development": return sqlite{ database: make(map[string]string), } default: return nil } } func AbstractFactory(fact string) Factory { switch fact { case "database": return DatabaseFactory case "filesystem": return FilesystemFactory default: return nil } }3.优缺点工厂模式优点缺点可以避免创建者和具体产品之间的紧密耦合应用工厂方法模式需要引入许多新的子类, 代码可能会因此变得更复杂。 最好的情况是将该模式引入创建者类的现有层次结构中单一职责原则,你可以将产品创建代码放在程序的单一位置,从而使得代码更容易维护 开闭原则,无需更改现有客户端代码,你就可以在程序中引入新的产品类型 抽象工厂优点缺点可以确保同一工厂生成的产品相互匹配由于采用该模式需要向应用中引入众多接口和类,代码可能会比之前更加复杂可以避免客户端和具体产品代码的耦合 单一职责原则,你可以将产品生成代码抽取到同一位置,使得代码易于维护 开闭原则,向应用程序中引入新产品变体时,你无需修改客户端代码 {/collapse-item}{/collapse}