搜索到
2
篇与
的结果
-
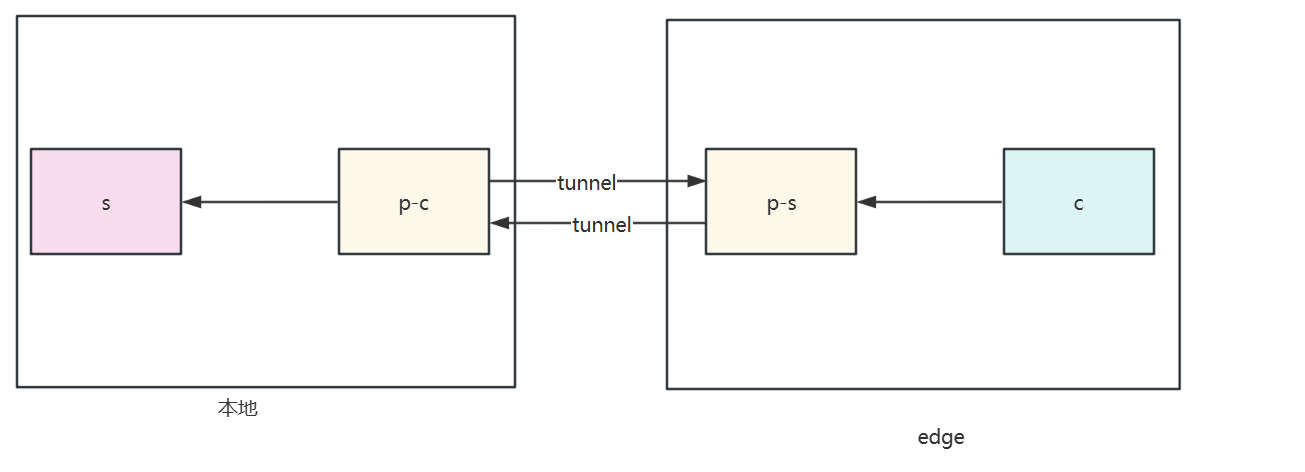
![Proxy Protocol Performance Testing Comparison(yamux/smux/h2)]() Proxy Protocol Performance Testing Comparison(yamux/smux/h2) 测试环境测试组件包括:请求发起端(client)、请求接收端(server)和代理组件客户端(proxy client)和代理组件服务端(proxy server)。测试目的:对比proxy client和proxy serve之间使用不同的协议对请求的影响。将client -> proxy client和proxy server -> server之间的网络影响降至最低,所以测试时将client和proxy client放在同一台主机host1上,将proxy server和server放在同一台主机host2上。两台4C8G的linux设备测试结果下面测试为proxy client 和 proxy server之间没有丢包的情况下,分别测试proxy client 和 proxy server之间的RTT为10ms、100ms、200ms、500ms情况下,四种协议的单个请求的平均耗时(总请求数量为10000)。{lamp/}RTT 10ms{lamp/}RTT 100ms{lamp/}RTT 200ms{lamp/}RTT 500ms前3000个请求是因为需要openstream导致的 建立了1000的并发建立了1000个stream,每个stream发送10个请求,去除建立stream的10ms rtt数据如下{lamp/}拉流传输性能iperf3测试一分钟传输性能每秒大概发送500MB数据测试传输数据不同延时下载大文件{lamp/}h2RTT/1G文件speedtime<1ms223MB/s4.6s100ms28.7MB/s54s500ms6.32MB/s3m 8syamuxRTT/1G文件speedtime<1ms144MB/s7.0s100ms9.71MB/s1m 49s500ms1.98MB/s8m 42stcpRTT/1G文件speedtime<1ms256MB/s4.1s100ms29.1MB/s36s500ms6.33MB/s2m 57s结论:随着代理组件(proxy client和proxy server)间的RTT增大,smux、http2的单个请求平均耗时差距小。smux 在传输性能和最大带宽方面表现最佳,但其波动稍大于 h2。h2 在传输稳定性方面表现最佳,其平均带宽和最大带宽也很高。yamux 的平均带宽和稳定性较差,可能不太适合高性能要求的场景。
Proxy Protocol Performance Testing Comparison(yamux/smux/h2) 测试环境测试组件包括:请求发起端(client)、请求接收端(server)和代理组件客户端(proxy client)和代理组件服务端(proxy server)。测试目的:对比proxy client和proxy serve之间使用不同的协议对请求的影响。将client -> proxy client和proxy server -> server之间的网络影响降至最低,所以测试时将client和proxy client放在同一台主机host1上,将proxy server和server放在同一台主机host2上。两台4C8G的linux设备测试结果下面测试为proxy client 和 proxy server之间没有丢包的情况下,分别测试proxy client 和 proxy server之间的RTT为10ms、100ms、200ms、500ms情况下,四种协议的单个请求的平均耗时(总请求数量为10000)。{lamp/}RTT 10ms{lamp/}RTT 100ms{lamp/}RTT 200ms{lamp/}RTT 500ms前3000个请求是因为需要openstream导致的 建立了1000的并发建立了1000个stream,每个stream发送10个请求,去除建立stream的10ms rtt数据如下{lamp/}拉流传输性能iperf3测试一分钟传输性能每秒大概发送500MB数据测试传输数据不同延时下载大文件{lamp/}h2RTT/1G文件speedtime<1ms223MB/s4.6s100ms28.7MB/s54s500ms6.32MB/s3m 8syamuxRTT/1G文件speedtime<1ms144MB/s7.0s100ms9.71MB/s1m 49s500ms1.98MB/s8m 42stcpRTT/1G文件speedtime<1ms256MB/s4.1s100ms29.1MB/s36s500ms6.33MB/s2m 57s结论:随着代理组件(proxy client和proxy server)间的RTT增大,smux、http2的单个请求平均耗时差距小。smux 在传输性能和最大带宽方面表现最佳,但其波动稍大于 h2。h2 在传输稳定性方面表现最佳,其平均带宽和最大带宽也很高。yamux 的平均带宽和稳定性较差,可能不太适合高性能要求的场景。 -
![性能压测整理]() 性能压测整理 1 测试指标根据服务实际情况选择需要评估指标进行衡量1.1 CPU性能1.1.1 CPU 使用率用户CPU使用率系统CPU使用率iowait CPU使用率软中断和硬中断的 CPU 使用率数据数据数据数据数据数据数据数据{lamp/}用户 CPU 使用率,包括用户态 CPU 使用率(user)和低优先级用户态 CPU 使用率(nice),表示 CPU 在用户态运行的时间百分比。用户 CPU 使用率高,通常说明有应用程序比较繁忙。系统 CPU 使用率,表示 CPU 在内核态运行的时间百分比(不包括中断)。系统 CPU 使用率高,说明内核比较繁忙。等待 I/O 的 CPU 使用率,通常也称为 iowait,表示等待 I/O 的时间百分比。iowait 高,通常说明系统与硬件设备的 I/O 交互时间比较长。软中断和硬中断的 CPU 使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断。统计数据的方式top用户CPU使用率 = us + ni系统CPU使用率 = syiowait CPU使用率 = wa软中断和硬中断的 CPU 使用率 = si + hi1.1.2 平均负载指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数1min5min15min数据数据数据数据数据数据衡量负载的标准需要根据当前的cpu数来进行比较,需要先计算出当前服务所在服务器上的cpu数来衡量grep 'model name' /proc/cpuinfo | wc -l例:假设我们在一个单 CPU 系统上看到平均负载为 1.73,0.60,7.98,那么说明在过去 1 分钟内,系统有 73% 的超载,而在 15 分钟内,有 698% 的超载,从整体趋势来看,系统的负载在降低(超载量=平均负载- CPU数量)如果 1 分钟、5 分钟、15 分钟的三个值基本相同,或者相差不大,那就说明系统负载很平稳。如果 1 分钟的值远小于 15 分钟的值,就说明系统最近 1 分钟的负载在减少,而过去 15 分钟内却有很大的负载。如果 1 分钟的值远大于 15 分钟的值,就说明最近 1 分钟的负载在增加,这种增加有可能只是临时性的,也有可能还会持续增加下去,所以就需要持续观察。一旦 1 分钟的平均负载接近或超过了 CPU 的个数,就意味着系统正在发生过载的问题,这时就得分析调查是哪里导致的问题,并要想办法优化了统计数据的方式uptime //或者top后面三个数字,依次则是过去 1 分钟、5 分钟、15 分钟的平均负载1.2 内存性能1.2.1 系统内存性能totalusedfreesharedbuff/cacheavailable表格表格表格表格表格表格表格表格表格表格表格表格total 是总内存大小used 是已使用内存的大小,包含了共享内存free 是未使用内存的大小 shared 是共享内存的大小buff/cache 是缓存和缓冲区的大小available 是新进程可用内存的大小。统计数据的方式free -h1.2.2 程序内存性能VIRTRESSHR%MEM表格表格表格表格表格表格表格表格VIRT 是进程虚拟内存的大小,只要是进程申请过的内存,即便还没有真正分配物理内存,也会计算在内。RES 是常驻内存的大小,也就是进程实际使用的物理内存大小,但不包括 Swap 和共享内存。SHR 是共享内存的大小,比如与其他进程共同使用的共享内存、加载的动态链接库以及程序的代码段等。共享内存 SHR 并不一定是共享的,比方说,程序的代码段、非共享的动态链接库,也都算在 SHR 里。当然,SHR 也包括了进程间真正共享的内存。所以在计算多个进程的内存使用时,不要把所有进程的 SHR 直接相加得出结果%MEM 是进程使用物理内存占系统总内存的百分比。统计数据的方式top1.3 网络性能1.3.1 网络层和数据链路层转发性能 在这两个网络协议层中,每秒可处理的网络包数 PPS,就是最重要的性能指标。特别是 64B 小包的处理能力,需要特别测试。测试工具推荐 pktgen所用时间网络包数量PPS吞吐量错误数表格表格表格表格表格表格表格表格表格表格1.3.2 传输层TCP/UDP 性能测试工具推荐 iperf 或者 netperfiPerf - iPerf3 and iPerf2 user documentationCare and Feeding of Netperf 2.7.X压测一段时间记录pps和吞吐率数字1表示每隔1秒输出一组数据sar -n DEV 1吞吐量PPS表格表格表格表格rxpck/s 和 txpck/s 分别是接收和发送的 PPS,单位为包 / 秒。rxkB/s 和 txkB/s 分别是接收和发送的吞吐量,单位是 KB/ 秒。rxcmp/s 和 txcmp/s 分别是接收和发送的压缩数据包数,单位是包 / 秒。%ifutil 是网络接口的使用率,即半双工模式下为 (rxkB/s+txkB/s)/Bandwidth,而全双工模式下为 max(rxkB/s, txkB/s)/Bandwidth1.3.3 应用层HTTP/HTTPS 性能测试工具推荐 wrk相对ab和iperf这类工具来说,wrk可以嵌入lua脚本,给请求增加payload,更接近实际应用场景,测出服务的真实性能。-c表示并发连接数1000,-t表示线程数为2,-d表示测试持续时间单位swrk -c 1000 -t 2 -d 300s --latency http://192.168.1.1/ #wrk 安装方式 https://github.com/wg/wrk cd wrk apt-get install build-essential -y make sudo cp wrk /usr/local/bin/QPS吞吐率请求总数请求失败总数请求成功率表格表格表格表格表格表格表格表格表格表格请求延迟的分布50%75%90%99%表格表格表格表格表格表格表格表格附上延时分布条形图8 threads and 200 connections (共8个测试线程,200个连接)Thread Stats Avg Stdev Max +/- Stdev (平均值) (标准差)(最大值)(正负一个标准差所占比例) Latency 46.67ms 215.38ms 1.67s 95.59% (延迟) Req/Sec 7.91k 1.15k 10.26k 70.77% (处理中的请求数) Latency Distribution (延迟分布) 50% 2.93ms 75% 3.78ms 90% 4.73ms 99% 1.35s (99分位的延迟:%99的请求在1.35s以内) 1790465 requests in 30.01s, 684.08MB read (30.01秒内共处理完成了1790465个请求,读取了684.08MB数据) Requests/sec: 59658.29 (平均每秒处理完成59658.29个请求) Transfer/sec: 22.79MB (平均每秒读取数据22.79MB)先使用单线程不断增加连接数,直到QPS保持稳定或响应时间超过业务要求限制。在当期数值取得单线程最优连接数。 单个连接线程数保持不变,不断增加线程数(建议到CPU核心数为止即可),直到整体出现QPS水平。如果QPS没有出现随着线程数增长则是目标服务器性能已经达到瓶颈,wrk单线程即可压测出目标机器最优QPS。如果QPS一直没有出现水平趋势,则说明wrk压测机性能出现了瓶颈,需要扩大wrk压测机性能或者增加压测机器集群。运行 wrk 的机器必须有足够数量的可用临时端口,并且应该快速回收关闭的套接字。 为了处理初始连接突增,服务器的 listen(2) backlog 应该大于正在测试的并发连接数。测试短链接并发连接数Releases · link1st/go-stress-testing · GitHub-c 表示并发数-n 每个并发执行请求的次数,总请求的次数 = 并发数 * 每个并发执行请求的次数-u 需要压测的地址运行 以mac为示例./go-stress-testing-mac -c 1 -n 100 -u https://www.baidu.com/
性能压测整理 1 测试指标根据服务实际情况选择需要评估指标进行衡量1.1 CPU性能1.1.1 CPU 使用率用户CPU使用率系统CPU使用率iowait CPU使用率软中断和硬中断的 CPU 使用率数据数据数据数据数据数据数据数据{lamp/}用户 CPU 使用率,包括用户态 CPU 使用率(user)和低优先级用户态 CPU 使用率(nice),表示 CPU 在用户态运行的时间百分比。用户 CPU 使用率高,通常说明有应用程序比较繁忙。系统 CPU 使用率,表示 CPU 在内核态运行的时间百分比(不包括中断)。系统 CPU 使用率高,说明内核比较繁忙。等待 I/O 的 CPU 使用率,通常也称为 iowait,表示等待 I/O 的时间百分比。iowait 高,通常说明系统与硬件设备的 I/O 交互时间比较长。软中断和硬中断的 CPU 使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断。统计数据的方式top用户CPU使用率 = us + ni系统CPU使用率 = syiowait CPU使用率 = wa软中断和硬中断的 CPU 使用率 = si + hi1.1.2 平均负载指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数1min5min15min数据数据数据数据数据数据衡量负载的标准需要根据当前的cpu数来进行比较,需要先计算出当前服务所在服务器上的cpu数来衡量grep 'model name' /proc/cpuinfo | wc -l例:假设我们在一个单 CPU 系统上看到平均负载为 1.73,0.60,7.98,那么说明在过去 1 分钟内,系统有 73% 的超载,而在 15 分钟内,有 698% 的超载,从整体趋势来看,系统的负载在降低(超载量=平均负载- CPU数量)如果 1 分钟、5 分钟、15 分钟的三个值基本相同,或者相差不大,那就说明系统负载很平稳。如果 1 分钟的值远小于 15 分钟的值,就说明系统最近 1 分钟的负载在减少,而过去 15 分钟内却有很大的负载。如果 1 分钟的值远大于 15 分钟的值,就说明最近 1 分钟的负载在增加,这种增加有可能只是临时性的,也有可能还会持续增加下去,所以就需要持续观察。一旦 1 分钟的平均负载接近或超过了 CPU 的个数,就意味着系统正在发生过载的问题,这时就得分析调查是哪里导致的问题,并要想办法优化了统计数据的方式uptime //或者top后面三个数字,依次则是过去 1 分钟、5 分钟、15 分钟的平均负载1.2 内存性能1.2.1 系统内存性能totalusedfreesharedbuff/cacheavailable表格表格表格表格表格表格表格表格表格表格表格表格total 是总内存大小used 是已使用内存的大小,包含了共享内存free 是未使用内存的大小 shared 是共享内存的大小buff/cache 是缓存和缓冲区的大小available 是新进程可用内存的大小。统计数据的方式free -h1.2.2 程序内存性能VIRTRESSHR%MEM表格表格表格表格表格表格表格表格VIRT 是进程虚拟内存的大小,只要是进程申请过的内存,即便还没有真正分配物理内存,也会计算在内。RES 是常驻内存的大小,也就是进程实际使用的物理内存大小,但不包括 Swap 和共享内存。SHR 是共享内存的大小,比如与其他进程共同使用的共享内存、加载的动态链接库以及程序的代码段等。共享内存 SHR 并不一定是共享的,比方说,程序的代码段、非共享的动态链接库,也都算在 SHR 里。当然,SHR 也包括了进程间真正共享的内存。所以在计算多个进程的内存使用时,不要把所有进程的 SHR 直接相加得出结果%MEM 是进程使用物理内存占系统总内存的百分比。统计数据的方式top1.3 网络性能1.3.1 网络层和数据链路层转发性能 在这两个网络协议层中,每秒可处理的网络包数 PPS,就是最重要的性能指标。特别是 64B 小包的处理能力,需要特别测试。测试工具推荐 pktgen所用时间网络包数量PPS吞吐量错误数表格表格表格表格表格表格表格表格表格表格1.3.2 传输层TCP/UDP 性能测试工具推荐 iperf 或者 netperfiPerf - iPerf3 and iPerf2 user documentationCare and Feeding of Netperf 2.7.X压测一段时间记录pps和吞吐率数字1表示每隔1秒输出一组数据sar -n DEV 1吞吐量PPS表格表格表格表格rxpck/s 和 txpck/s 分别是接收和发送的 PPS,单位为包 / 秒。rxkB/s 和 txkB/s 分别是接收和发送的吞吐量,单位是 KB/ 秒。rxcmp/s 和 txcmp/s 分别是接收和发送的压缩数据包数,单位是包 / 秒。%ifutil 是网络接口的使用率,即半双工模式下为 (rxkB/s+txkB/s)/Bandwidth,而全双工模式下为 max(rxkB/s, txkB/s)/Bandwidth1.3.3 应用层HTTP/HTTPS 性能测试工具推荐 wrk相对ab和iperf这类工具来说,wrk可以嵌入lua脚本,给请求增加payload,更接近实际应用场景,测出服务的真实性能。-c表示并发连接数1000,-t表示线程数为2,-d表示测试持续时间单位swrk -c 1000 -t 2 -d 300s --latency http://192.168.1.1/ #wrk 安装方式 https://github.com/wg/wrk cd wrk apt-get install build-essential -y make sudo cp wrk /usr/local/bin/QPS吞吐率请求总数请求失败总数请求成功率表格表格表格表格表格表格表格表格表格表格请求延迟的分布50%75%90%99%表格表格表格表格表格表格表格表格附上延时分布条形图8 threads and 200 connections (共8个测试线程,200个连接)Thread Stats Avg Stdev Max +/- Stdev (平均值) (标准差)(最大值)(正负一个标准差所占比例) Latency 46.67ms 215.38ms 1.67s 95.59% (延迟) Req/Sec 7.91k 1.15k 10.26k 70.77% (处理中的请求数) Latency Distribution (延迟分布) 50% 2.93ms 75% 3.78ms 90% 4.73ms 99% 1.35s (99分位的延迟:%99的请求在1.35s以内) 1790465 requests in 30.01s, 684.08MB read (30.01秒内共处理完成了1790465个请求,读取了684.08MB数据) Requests/sec: 59658.29 (平均每秒处理完成59658.29个请求) Transfer/sec: 22.79MB (平均每秒读取数据22.79MB)先使用单线程不断增加连接数,直到QPS保持稳定或响应时间超过业务要求限制。在当期数值取得单线程最优连接数。 单个连接线程数保持不变,不断增加线程数(建议到CPU核心数为止即可),直到整体出现QPS水平。如果QPS没有出现随着线程数增长则是目标服务器性能已经达到瓶颈,wrk单线程即可压测出目标机器最优QPS。如果QPS一直没有出现水平趋势,则说明wrk压测机性能出现了瓶颈,需要扩大wrk压测机性能或者增加压测机器集群。运行 wrk 的机器必须有足够数量的可用临时端口,并且应该快速回收关闭的套接字。 为了处理初始连接突增,服务器的 listen(2) backlog 应该大于正在测试的并发连接数。测试短链接并发连接数Releases · link1st/go-stress-testing · GitHub-c 表示并发数-n 每个并发执行请求的次数,总请求的次数 = 并发数 * 每个并发执行请求的次数-u 需要压测的地址运行 以mac为示例./go-stress-testing-mac -c 1 -n 100 -u https://www.baidu.com/