搜索到
51
篇与
的结果
-
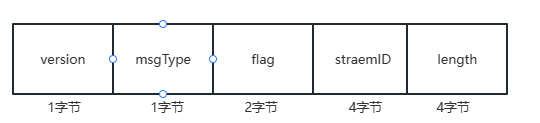
![yamux: how to work?]() yamux: how to work? {collapse}{collapse-item label="一、项目地址" open} giuthub:yamux {/collapse-item}{collapse-item label="二、消息格式" open}yamux头部数据flag的类型消息类型{/collapse-item}{collapse-item label="三、数据交互流程" open} 1.双方tcp三次握手完成之后,客户端发起处理请求需要创建一个新的stream,客户端发送yamux封装的syn包给服务端,这个封装的包是12个字节,服务端回复ack2.服务端收到客户端yamux封装的syn包后,封装yamux的syn ack包给客户端,这个封装的包是12个字节,客户端回复ack,此时双方共识了这个stream3.客户端或者服务端需要发送数据给对方时,需要先发送一个yamux封装的数据包头,12个字节,指明要发送的数据的长度,对方回应一个ack,之后就开始发送数据包{/collapse-item}{collapse-item label="四、调用read收包原理" open} 创建完一个stream之后,返回的是一个net.conn类型的接口,收数据包时,调用net.conn接口的read时,实际上调用的是stream对象的read,stream的read使用goto的方法判断recvBuf有没有数据,有数据将数据拷贝给read函数的参数buf中,并返回拷贝的数据大小在recvloop的协程中通过io.readFull从soket中收到数据包头时,根据数据包头的消息类型调用提前绑定好的函数,如果数据类型是data类型,则会调用readData函数,将数据拷贝到recvBuf中{/collapse-item}{/collapse}
yamux: how to work? {collapse}{collapse-item label="一、项目地址" open} giuthub:yamux {/collapse-item}{collapse-item label="二、消息格式" open}yamux头部数据flag的类型消息类型{/collapse-item}{collapse-item label="三、数据交互流程" open} 1.双方tcp三次握手完成之后,客户端发起处理请求需要创建一个新的stream,客户端发送yamux封装的syn包给服务端,这个封装的包是12个字节,服务端回复ack2.服务端收到客户端yamux封装的syn包后,封装yamux的syn ack包给客户端,这个封装的包是12个字节,客户端回复ack,此时双方共识了这个stream3.客户端或者服务端需要发送数据给对方时,需要先发送一个yamux封装的数据包头,12个字节,指明要发送的数据的长度,对方回应一个ack,之后就开始发送数据包{/collapse-item}{collapse-item label="四、调用read收包原理" open} 创建完一个stream之后,返回的是一个net.conn类型的接口,收数据包时,调用net.conn接口的read时,实际上调用的是stream对象的read,stream的read使用goto的方法判断recvBuf有没有数据,有数据将数据拷贝给read函数的参数buf中,并返回拷贝的数据大小在recvloop的协程中通过io.readFull从soket中收到数据包头时,根据数据包头的消息类型调用提前绑定好的函数,如果数据类型是data类型,则会调用readData函数,将数据拷贝到recvBuf中{/collapse-item}{/collapse} -
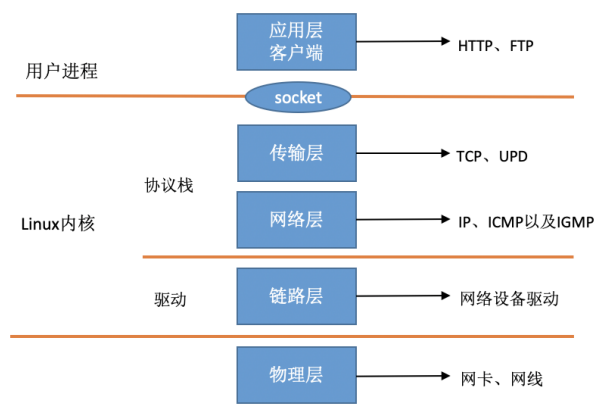
![How to receive a network packet in Linux]() How to receive a network packet in Linux {collapse}{collapse-item label=" 一、简介 " open}在TCP/IP ⽹络分层模型⾥,整个协议栈被分成了物理层、链路层、⽹络层,传输层和应⽤层。物理层对应的是⽹卡和⽹线,应⽤层对应的是我们常⻅的 Nginx,FTP 等等各种应⽤。Linux 实现的是链路层、⽹络层和传输层这三层。在 Linux 内核实现中,链路层协议靠⽹卡驱动来实现,内核协议栈来实现⽹络层和传输层。内核对更上层的应⽤层提供 socket 接⼝来供⽤户进程访问。在 Linux 的源代码中,⽹络设备驱动对应的逻辑位于 driver/net/ethernet , 其中 intel 系列⽹卡的驱动在 driver/net/ethernet/intel ⽬录下。协议栈模块代码位于 kernel 和 net ⽬录。{lamp/}此Linux中断处理函数是分上半部和下半部的。上半部是只进⾏最简单的⼯作,快速处理然后释放 CPU ,接着 CPU 就可以允许其它中断进来。剩下将绝⼤部分的⼯作都放到下半部中。2.4 以后的内核版本采⽤的下半部实现⽅式是软中断,由 ksoftirqd 内核线程全权处理。和硬中断不同的是,硬中断是通过给 CPU 物理引脚施加电压变化,⽽软中断是通过给内存中的⼀个变量的⼆进制值以通知软中断处理程序。当⽹卡上收到数据以后,Linux 中第⼀个⼯作的模块是⽹络驱动。 ⽹络驱动会以 DMA 的⽅式把⽹卡上收到的帧写到内存⾥。再向 CPU 发起⼀个中断,以通知 CPU 有数据到达。第⼆,当 CPU 收到中断请求后,会去调⽤⽹络驱动注册的中断处理函数。 ⽹卡的中断处理函数并不做过多⼯作,发出软中断请求,然后尽快释放 CPU。ksoftirqd 检测到有软中断请求到达,调⽤ poll 开始轮询收包,收到后交由各级协议栈处理。对于 udp 包来说,会被放到⽤户 socket 的接收队列中。{/collapse-item}{collapse-item label=" 二、linux启动 " open} 1. 创建ksoftirqd内核进程 系统初始化的时候在 kernel/smpboot.c中调⽤了 smpboot_register_percpu_thread, 该函数进⼀步会执⾏到 spawn_ksoftirqd(位于kernel/softirq.c)来创建出 softirqd 进程。//file: kernel/softirq.c static struct smp_hotplug_thread softirq_threads = { .store = &ksoftirqd, .thread_should_run = ksoftirqd_should_run, .thread_fn = run_ksoftirqd, .thread_comm = "ksoftirqd/%u", }; static __init int spawn_ksoftirqd(void) { register_cpu_notifier(&cpu_nfb); BUG_ON(smpboot_register_percpu_thread(&softirq_threads)); return 0; } early_initcall(spawn_ksoftirqd);2. 网络子系统初始化 //file: net/core/dev.c static int __init net_dev_init(void) { ...... for_each_possible_cpu(i) { struct softnet_data *sd = &per_cpu(softnet_data, i); memset(sd, 0, sizeof(*sd)); skb_queue_head_init(&sd->input_pkt_queue); skb_queue_head_init(&sd->process_queue); sd->completion_queue = NULL; INIT_LIST_HEAD(&sd->poll_list); ...... } ...... open_softirq(NET_TX_SOFTIRQ, net_tx_action); open_softirq(NET_RX_SOFTIRQ, net_rx_action); } subsys_initcall(net_dev_init);2.1 linux 内核通过调⽤ subsys_initcall 来初始化各个⼦系统,在源代码⽬录⾥你可以 grep 出许多对这个函数的调⽤。2.2 网络子系统初始化的时候会为每个 CPU 都申请⼀个 softnet_data 数据结构,在这个数据结构⾥的poll_list 是等待驱动程序将其 poll 函数注册进来。2.3 open_softirq 注册了每⼀种软中断都注册⼀个处理函数, NET_TX_SOFTIRQ 的处理函数为net_tx_action,NET_RX_SOFTIRQ 的为 net_rx_action。open_softirq 注册的⽅式是记录在 softirq_vec 变量⾥的。ksoftirqd 线程收到软中断的时候,也会使⽤这个变量来找到每⼀种软中断对应的处理函数。3. 协议栈注册 内核实现了网络层的IP协议、传输层的TCP协议和UDP协议,这些协议对应的实现函数分别是 ip_rcv(), tcp_v4_rcv()和 udp_rcv()。内核是通过注册的⽅式来实现的, Linux 内核中的 fs_initcall 和 subsys_initcall 类似,也是初始化模块的⼊⼝。 fs_initcall 调⽤ inet_init 后开始⽹络协议栈注册。 通过 inet_init ,将这些函数注册到了 inet_protos 和 ptype_base 数据结构中了。//file: net/ipv4/af_inet.c static struct packet_type ip_packet_type __read_mostly = { .type = cpu_to_be16(ETH_P_IP), .func = ip_rcv, }; static const struct net_protocol udp_protocol = { .handler = udp_rcv, .err_handler = udp_err, .no_policy = 1, .netns_ok = 1, }; static const struct net_protocol tcp_protocol = { .early_demux = tcp_v4_early_demux, .handler = tcp_v4_rcv, .err_handler = tcp_v4_err, .no_policy = 1, .netns_ok = 1, }; static int __init inet_init(void) { ...... if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0) pr_crit("%s: Cannot add ICMP protocol\n", __func__); if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0) pr_crit("%s: Cannot add UDP protocol\n", __func__); if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0) pr_crit("%s: Cannot add TCP protocol\n", __func__); ...... dev_add_pack(&ip_packet_type); }inet_protos 记录着 udp,tcp 的处理函数地址,ptype_base 存储着 ip_rcv() 函数的处理地址4. ⽹卡驱动初始化 每⼀个驱动程序(不仅仅只是⽹卡驱动)会使⽤ module_init 向内核注册⼀个初始化函数,当驱动被加载时,内核会调⽤这个函数。//file: drivers/net/ethernet/intel/igb/igb_main.c static struct pci_driver igb_driver = { .name = igb_driver_name, .id_table = igb_pci_tbl, .probe = igb_probe, .remove = igb_remove, ...... }; static int __init igb_init_module(void) { ...... ret = pci_register_driver(&igb_driver); return ret; }第2步中驱动probe让驱动处于ready第5步中⽹卡驱动实现了 ethtool 所需要的接⼝,也在这⾥注册完成函数地址的注册。当ethtool 发起⼀个系统调⽤,内核会找到对应操作回调函数第6步注册的 igb_netdev_ops 中包含的是 igb_open 等函数,该函数在⽹卡被启动的时候会被调⽤5. 启动⽹卡 当上⾯的初始化都完成以后,就可以启动⽹卡了。//file: drivers/net/ethernet/intel/igb/igb_main.c static int __igb_open(struct net_device *netdev, bool resuming) { /* allocate transmit descriptors */ err = igb_setup_all_tx_resources(adapter); /* allocate receive descriptors */ err = igb_setup_all_rx_resources(adapter); /* 注册中断处理函数 */ err = igb_request_irq(adapter); if (err) goto err_req_irq; /* 启⽤NAPI */ for (i = 0; i < adapter->num_q_vectors; i++) napi_enable(&(adapter->q_vector[i]->napi)); ...... }{/collapse-item}{collapse-item label=" 二、收包流程 " open} 1. 硬中断处理 ⾸先当数据帧从⽹线到达⽹卡上的时候,第⼀站是⽹卡的接收队列。⽹卡在分配给⾃⼰的 RingBuffer中寻找可⽤的内存位置,找到后 DMA 引擎会把数据 DMA 到⽹卡之前关联的内存⾥,这个时候 CPU都是⽆感的。当 DMA 操作完成以后,⽹卡会向 CPU 发起⼀个硬中断,通知 CPU 有数据到达。2. ksoftirqd 内核线程处理软中断 内核线程初始化的时候,我们介绍了 ksoftirqd 中两个线程函数 ksoftirqd_should_run 和run_ksoftirqd 。static int ksoftirqd_should_run(unsigned int cpu) { return local_softirq_pending(); } #define local_softirq_pending() \ __IRQ_STAT(smp_processor_id(), __softirq_pending)这⾥看到和硬中断中调⽤了同⼀个函数 local_softirq_pending 。使⽤⽅式不同的是硬中断位置是为了写⼊标记,这⾥仅仅只是读取。如果硬中断中设置了 NET_RX_SOFTIRQ ,这⾥⾃然能读取的到。static void run_ksoftirqd(unsigned int cpu) { local_irq_disable(); if (local_softirq_pending()) { __do_softirq(); rcu_note_context_switch(cpu); local_irq_enable(); cond_resched(); return; } local_irq_enable(); }在 __do_softirq 中,判断根据当前 CPU 的软中断类型,调⽤其注册的 action ⽅法。asmlinkage void __do_softirq(void) { do { if (pending & 1) { unsigned int vec_nr = h - softirq_vec; int prev_count = preempt_count(); ... trace_softirq_entry(vec_nr); h->action(h); trace_softirq_exit(vec_nr); ... } h++; pending >>= 1; } while (pending); }硬中断中设置软中断标记,和 ksoftirq 的判断是否有软中断到达,都是基于smp_processor_id() 的。这意味着只要硬中断在哪个 CPU 上被响应,那么软中断也是在这个 CPU 上处理的。如果你发现你的 Linux 软中断 CPU 消耗都集中在⼀个核上的话,做法是要把调整硬中断的 CPU 亲和性,来将硬中断打散到不同的 CPU 核上去。//file:net/core/dev.c static void net_rx_action(struct softirq_action *h) { struct softnet_data *sd = &__get_cpu_var(softnet_data); unsigned long time_limit = jiffies + 2; int budget = netdev_budget; void *have; local_irq_disable(); while (!list_empty(&sd->poll_list)) { ...... n = list_first_entry(&sd->poll_list, struct napi_struct, poll_list); work = 0; if (test_bit(NAPI_STATE_SCHED, &n->state)) { work = n->poll(n, weight); trace_napi_poll(n); } budget -= work;net_rx_action } }函数开头的 time_limit 和 budget 是⽤来控制 net_rx_action 函数主动退出的,⽬的是保证⽹络包的接收不霸占 CPU 不放。 等下次⽹卡再有硬中断过来的时候再处理剩下的接收数据包。其中 budget 可以通过内核参数调整。 这个函数中剩下的核⼼逻辑是获取到当前 CPU 变量 softnet_data,对其 poll_list进⾏遍历, 然后执⾏到⽹卡驱动注册到的 poll 函数。对于 igb ⽹卡来说,就是 igb 驱动⾥的igb_poll 函数了。/** * igb_poll - NAPI Rx polling callback * @napi: napi polling structure * @budget: count of how many packets we should handle **/ static int igb_poll(struct napi_struct *napi, int budget) { ... if (q_vector->tx.ring) clean_complete = igb_clean_tx_irq(q_vector); if (q_vector->rx.ring) clean_complete &= igb_clean_rx_irq(q_vector, budget); ... }在读取操作中, igb_poll 的重点⼯作是对 igb_clean_rx_irq 的调⽤。static bool igb_clean_rx_irq(struct igb_q_vector *q_vector, const int budget) { ... do { /* retrieve a buffer from the ring */ skb = igb_fetch_rx_buffer(rx_ring, rx_desc, skb); /* fetch next buffer in frame if non-eop */ if (igb_is_non_eop(rx_ring, rx_desc)) continue; } /* verify the packet layout is correct */ if (igb_cleanup_headers(rx_ring, rx_desc, skb)) { skb = NULL; continue; } /* populate checksum, timestamp, VLAN, and protocol */ igb_process_skb_fields(rx_ring, rx_desc, skb); napi_gro_receive(&q_vector->napi, skb); }igb_fetch_rx_buffer 和 igb_is_non_eop 的作⽤就是把数据帧从 RingBuffer 上取下来。为什么需要两个函数呢?因为有可能帧要占多个 RingBuffer,所以是在⼀个循环中获取的,直到帧尾部。获取下来的⼀个数据帧⽤⼀个 sk_buff 来表示。收取完数据以后,对其进⾏⼀些校验,然后开始设置 sbk 变量的 timestamp, VLAN id, protocol 等字段。//file: net/core/dev.c gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb) { skb_gro_reset_offset(skb); return napi_skb_finish(dev_gro_receive(napi, skb), skb); }dev_gro_receive 这个函数代表的是⽹卡 GRO 特性,可以简单理解成把相关的⼩包合并成⼀个⼤包就⾏,⽬的是减少传送给⽹络栈的包数,这有助于减少 CPU 的使⽤量。我们暂且忽略,直接看napi_skb_finish , 这个函数主要就是调⽤了 netif_receive_skb 。//file: net/core/dev.c static gro_result_t napi_skb_finish(gro_result_t ret, struct sk_buff *skb) { switch (ret) { case GRO_NORMAL: if (netif_receive_skb(skb)) ret = GRO_DROP; break; ...... }在 netif_receive_skb 中,数据包将被送到协议栈中。3. ⽹络协议栈处理 netif_receive_skb 函数会根据包的协议,假如是 udp 包,会将包依次送到 ip_rcv(), udp_rcv() 协议处理函数中进⾏处理。//file: net/core/dev.c int netif_receive_skb(struct sk_buff *skb) { //RPS处理逻辑,先忽略 ...... return __netif_receive_skb(skb); } static int __netif_receive_skb(struct sk_buff *skb) { ...... ret = __netif_receive_skb_core(skb, false); } static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc) { ...... //pcap逻辑,这⾥会将数据送⼊抓包点。tcpdump就是从这个⼊⼝获取包的 list_for_each_entry_rcu(ptype, &ptype_all, list) { if (!ptype->dev || ptype->dev == skb->dev) { if (pt_prev) ret = deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype; } } ...... list_for_each_entry_rcu(ptype, &ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) { if (ptype->type == type && (ptype->dev == null_or_dev || ptype->dev == skb->dev || ptype->dev == orig_dev)) { if (pt_prev) ret = deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype; } } }__netif_receive_skb_core 取出 protocol,它会从数据包中取出协议信息,然后遍历注册在这个协议上的回调函数列表。//file: net/core/dev.c static inline int deliver_skb(struct sk_buff *skb, struct packet_type *pt_prev, struct net_device *orig_dev) { ...... return pt_prev->func(skb, skb->dev, pt_prev, orig_dev); }pt_prev->func 这⼀⾏就调⽤到了协议层注册的处理函数了。对于 ip 包来讲,就会进⼊到 ip_rcv(如果是arp包的话,会进⼊到arp_rcv)。4. IP 协议层处理//file: net/ipv4/ip_input.c int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev) { ...... return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, skb, dev, NULL, ip_rcv_finish); }这⾥ NF_HOOK 是⼀个钩⼦函数,当执⾏完注册的钩⼦后就会执⾏到最后⼀个参数指向的函数ip_rcv_finish 。static int ip_rcv_finish(struct sk_buff *skb) { ...... if (!skb_dst(skb)) { int err = ip_route_input_noref(skb, iph->daddr, iph->saddr, iph->tos, skb->dev); ... } ...... return dst_input(skb); }ip_route_input_noref 看到它⼜调⽤了 ip_route_input_mc 。 在 ip_route_input_mc中,函数 ip_local_deliver 被赋值给了 dst.input//file: net/ipv4/route.c static int ip_route_input_mc(struct sk_buff *skb, __be32 daddr, __be32 saddr, u8 tos, struct net_device *dev, int our) { if (our) { rth->dst.input= ip_local_deliver; rth->rt_flags |= RTCF_LOCAL; } }ip_rcv_finish 中的 return dst_input(skb)/* Input packet from network to transport. */ static inline int dst_input(struct sk_buff *skb) { return skb_dst(skb)->input(skb); }skb_dst(skb)->input 调⽤的 input ⽅法就是路由⼦系统赋的 ip_local_deliver。//file: net/ipv4/ip_input.c int ip_local_deliver(struct sk_buff *skb) { /* * Reassemble IP fragments. */ if (ip_is_fragment(ip_hdr(skb))) { if (ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER)) return 0; } return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, skb, skb->dev, NULL, ip_local_deliver_finish); } static int ip_local_deliver_finish(struct sk_buff *skb) { ...... int protocol = ip_hdr(skb)->protocol; const struct net_protocol *ipprot; ipprot = rcu_dereference(inet_protos[protocol]); if (ipprot != NULL) { ret = ipprot->handler(skb); } }net_protos 中保存着 tcp_v4_rcv() 和 udp_rcv() 的函数地址。这⾥将会根据包中的协议类型选择进⾏分发,在这⾥ skb 包将会进⼀步被派送到更上层的协议中, udp 和 tcp。{/collapse}
How to receive a network packet in Linux {collapse}{collapse-item label=" 一、简介 " open}在TCP/IP ⽹络分层模型⾥,整个协议栈被分成了物理层、链路层、⽹络层,传输层和应⽤层。物理层对应的是⽹卡和⽹线,应⽤层对应的是我们常⻅的 Nginx,FTP 等等各种应⽤。Linux 实现的是链路层、⽹络层和传输层这三层。在 Linux 内核实现中,链路层协议靠⽹卡驱动来实现,内核协议栈来实现⽹络层和传输层。内核对更上层的应⽤层提供 socket 接⼝来供⽤户进程访问。在 Linux 的源代码中,⽹络设备驱动对应的逻辑位于 driver/net/ethernet , 其中 intel 系列⽹卡的驱动在 driver/net/ethernet/intel ⽬录下。协议栈模块代码位于 kernel 和 net ⽬录。{lamp/}此Linux中断处理函数是分上半部和下半部的。上半部是只进⾏最简单的⼯作,快速处理然后释放 CPU ,接着 CPU 就可以允许其它中断进来。剩下将绝⼤部分的⼯作都放到下半部中。2.4 以后的内核版本采⽤的下半部实现⽅式是软中断,由 ksoftirqd 内核线程全权处理。和硬中断不同的是,硬中断是通过给 CPU 物理引脚施加电压变化,⽽软中断是通过给内存中的⼀个变量的⼆进制值以通知软中断处理程序。当⽹卡上收到数据以后,Linux 中第⼀个⼯作的模块是⽹络驱动。 ⽹络驱动会以 DMA 的⽅式把⽹卡上收到的帧写到内存⾥。再向 CPU 发起⼀个中断,以通知 CPU 有数据到达。第⼆,当 CPU 收到中断请求后,会去调⽤⽹络驱动注册的中断处理函数。 ⽹卡的中断处理函数并不做过多⼯作,发出软中断请求,然后尽快释放 CPU。ksoftirqd 检测到有软中断请求到达,调⽤ poll 开始轮询收包,收到后交由各级协议栈处理。对于 udp 包来说,会被放到⽤户 socket 的接收队列中。{/collapse-item}{collapse-item label=" 二、linux启动 " open} 1. 创建ksoftirqd内核进程 系统初始化的时候在 kernel/smpboot.c中调⽤了 smpboot_register_percpu_thread, 该函数进⼀步会执⾏到 spawn_ksoftirqd(位于kernel/softirq.c)来创建出 softirqd 进程。//file: kernel/softirq.c static struct smp_hotplug_thread softirq_threads = { .store = &ksoftirqd, .thread_should_run = ksoftirqd_should_run, .thread_fn = run_ksoftirqd, .thread_comm = "ksoftirqd/%u", }; static __init int spawn_ksoftirqd(void) { register_cpu_notifier(&cpu_nfb); BUG_ON(smpboot_register_percpu_thread(&softirq_threads)); return 0; } early_initcall(spawn_ksoftirqd);2. 网络子系统初始化 //file: net/core/dev.c static int __init net_dev_init(void) { ...... for_each_possible_cpu(i) { struct softnet_data *sd = &per_cpu(softnet_data, i); memset(sd, 0, sizeof(*sd)); skb_queue_head_init(&sd->input_pkt_queue); skb_queue_head_init(&sd->process_queue); sd->completion_queue = NULL; INIT_LIST_HEAD(&sd->poll_list); ...... } ...... open_softirq(NET_TX_SOFTIRQ, net_tx_action); open_softirq(NET_RX_SOFTIRQ, net_rx_action); } subsys_initcall(net_dev_init);2.1 linux 内核通过调⽤ subsys_initcall 来初始化各个⼦系统,在源代码⽬录⾥你可以 grep 出许多对这个函数的调⽤。2.2 网络子系统初始化的时候会为每个 CPU 都申请⼀个 softnet_data 数据结构,在这个数据结构⾥的poll_list 是等待驱动程序将其 poll 函数注册进来。2.3 open_softirq 注册了每⼀种软中断都注册⼀个处理函数, NET_TX_SOFTIRQ 的处理函数为net_tx_action,NET_RX_SOFTIRQ 的为 net_rx_action。open_softirq 注册的⽅式是记录在 softirq_vec 变量⾥的。ksoftirqd 线程收到软中断的时候,也会使⽤这个变量来找到每⼀种软中断对应的处理函数。3. 协议栈注册 内核实现了网络层的IP协议、传输层的TCP协议和UDP协议,这些协议对应的实现函数分别是 ip_rcv(), tcp_v4_rcv()和 udp_rcv()。内核是通过注册的⽅式来实现的, Linux 内核中的 fs_initcall 和 subsys_initcall 类似,也是初始化模块的⼊⼝。 fs_initcall 调⽤ inet_init 后开始⽹络协议栈注册。 通过 inet_init ,将这些函数注册到了 inet_protos 和 ptype_base 数据结构中了。//file: net/ipv4/af_inet.c static struct packet_type ip_packet_type __read_mostly = { .type = cpu_to_be16(ETH_P_IP), .func = ip_rcv, }; static const struct net_protocol udp_protocol = { .handler = udp_rcv, .err_handler = udp_err, .no_policy = 1, .netns_ok = 1, }; static const struct net_protocol tcp_protocol = { .early_demux = tcp_v4_early_demux, .handler = tcp_v4_rcv, .err_handler = tcp_v4_err, .no_policy = 1, .netns_ok = 1, }; static int __init inet_init(void) { ...... if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0) pr_crit("%s: Cannot add ICMP protocol\n", __func__); if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0) pr_crit("%s: Cannot add UDP protocol\n", __func__); if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0) pr_crit("%s: Cannot add TCP protocol\n", __func__); ...... dev_add_pack(&ip_packet_type); }inet_protos 记录着 udp,tcp 的处理函数地址,ptype_base 存储着 ip_rcv() 函数的处理地址4. ⽹卡驱动初始化 每⼀个驱动程序(不仅仅只是⽹卡驱动)会使⽤ module_init 向内核注册⼀个初始化函数,当驱动被加载时,内核会调⽤这个函数。//file: drivers/net/ethernet/intel/igb/igb_main.c static struct pci_driver igb_driver = { .name = igb_driver_name, .id_table = igb_pci_tbl, .probe = igb_probe, .remove = igb_remove, ...... }; static int __init igb_init_module(void) { ...... ret = pci_register_driver(&igb_driver); return ret; }第2步中驱动probe让驱动处于ready第5步中⽹卡驱动实现了 ethtool 所需要的接⼝,也在这⾥注册完成函数地址的注册。当ethtool 发起⼀个系统调⽤,内核会找到对应操作回调函数第6步注册的 igb_netdev_ops 中包含的是 igb_open 等函数,该函数在⽹卡被启动的时候会被调⽤5. 启动⽹卡 当上⾯的初始化都完成以后,就可以启动⽹卡了。//file: drivers/net/ethernet/intel/igb/igb_main.c static int __igb_open(struct net_device *netdev, bool resuming) { /* allocate transmit descriptors */ err = igb_setup_all_tx_resources(adapter); /* allocate receive descriptors */ err = igb_setup_all_rx_resources(adapter); /* 注册中断处理函数 */ err = igb_request_irq(adapter); if (err) goto err_req_irq; /* 启⽤NAPI */ for (i = 0; i < adapter->num_q_vectors; i++) napi_enable(&(adapter->q_vector[i]->napi)); ...... }{/collapse-item}{collapse-item label=" 二、收包流程 " open} 1. 硬中断处理 ⾸先当数据帧从⽹线到达⽹卡上的时候,第⼀站是⽹卡的接收队列。⽹卡在分配给⾃⼰的 RingBuffer中寻找可⽤的内存位置,找到后 DMA 引擎会把数据 DMA 到⽹卡之前关联的内存⾥,这个时候 CPU都是⽆感的。当 DMA 操作完成以后,⽹卡会向 CPU 发起⼀个硬中断,通知 CPU 有数据到达。2. ksoftirqd 内核线程处理软中断 内核线程初始化的时候,我们介绍了 ksoftirqd 中两个线程函数 ksoftirqd_should_run 和run_ksoftirqd 。static int ksoftirqd_should_run(unsigned int cpu) { return local_softirq_pending(); } #define local_softirq_pending() \ __IRQ_STAT(smp_processor_id(), __softirq_pending)这⾥看到和硬中断中调⽤了同⼀个函数 local_softirq_pending 。使⽤⽅式不同的是硬中断位置是为了写⼊标记,这⾥仅仅只是读取。如果硬中断中设置了 NET_RX_SOFTIRQ ,这⾥⾃然能读取的到。static void run_ksoftirqd(unsigned int cpu) { local_irq_disable(); if (local_softirq_pending()) { __do_softirq(); rcu_note_context_switch(cpu); local_irq_enable(); cond_resched(); return; } local_irq_enable(); }在 __do_softirq 中,判断根据当前 CPU 的软中断类型,调⽤其注册的 action ⽅法。asmlinkage void __do_softirq(void) { do { if (pending & 1) { unsigned int vec_nr = h - softirq_vec; int prev_count = preempt_count(); ... trace_softirq_entry(vec_nr); h->action(h); trace_softirq_exit(vec_nr); ... } h++; pending >>= 1; } while (pending); }硬中断中设置软中断标记,和 ksoftirq 的判断是否有软中断到达,都是基于smp_processor_id() 的。这意味着只要硬中断在哪个 CPU 上被响应,那么软中断也是在这个 CPU 上处理的。如果你发现你的 Linux 软中断 CPU 消耗都集中在⼀个核上的话,做法是要把调整硬中断的 CPU 亲和性,来将硬中断打散到不同的 CPU 核上去。//file:net/core/dev.c static void net_rx_action(struct softirq_action *h) { struct softnet_data *sd = &__get_cpu_var(softnet_data); unsigned long time_limit = jiffies + 2; int budget = netdev_budget; void *have; local_irq_disable(); while (!list_empty(&sd->poll_list)) { ...... n = list_first_entry(&sd->poll_list, struct napi_struct, poll_list); work = 0; if (test_bit(NAPI_STATE_SCHED, &n->state)) { work = n->poll(n, weight); trace_napi_poll(n); } budget -= work;net_rx_action } }函数开头的 time_limit 和 budget 是⽤来控制 net_rx_action 函数主动退出的,⽬的是保证⽹络包的接收不霸占 CPU 不放。 等下次⽹卡再有硬中断过来的时候再处理剩下的接收数据包。其中 budget 可以通过内核参数调整。 这个函数中剩下的核⼼逻辑是获取到当前 CPU 变量 softnet_data,对其 poll_list进⾏遍历, 然后执⾏到⽹卡驱动注册到的 poll 函数。对于 igb ⽹卡来说,就是 igb 驱动⾥的igb_poll 函数了。/** * igb_poll - NAPI Rx polling callback * @napi: napi polling structure * @budget: count of how many packets we should handle **/ static int igb_poll(struct napi_struct *napi, int budget) { ... if (q_vector->tx.ring) clean_complete = igb_clean_tx_irq(q_vector); if (q_vector->rx.ring) clean_complete &= igb_clean_rx_irq(q_vector, budget); ... }在读取操作中, igb_poll 的重点⼯作是对 igb_clean_rx_irq 的调⽤。static bool igb_clean_rx_irq(struct igb_q_vector *q_vector, const int budget) { ... do { /* retrieve a buffer from the ring */ skb = igb_fetch_rx_buffer(rx_ring, rx_desc, skb); /* fetch next buffer in frame if non-eop */ if (igb_is_non_eop(rx_ring, rx_desc)) continue; } /* verify the packet layout is correct */ if (igb_cleanup_headers(rx_ring, rx_desc, skb)) { skb = NULL; continue; } /* populate checksum, timestamp, VLAN, and protocol */ igb_process_skb_fields(rx_ring, rx_desc, skb); napi_gro_receive(&q_vector->napi, skb); }igb_fetch_rx_buffer 和 igb_is_non_eop 的作⽤就是把数据帧从 RingBuffer 上取下来。为什么需要两个函数呢?因为有可能帧要占多个 RingBuffer,所以是在⼀个循环中获取的,直到帧尾部。获取下来的⼀个数据帧⽤⼀个 sk_buff 来表示。收取完数据以后,对其进⾏⼀些校验,然后开始设置 sbk 变量的 timestamp, VLAN id, protocol 等字段。//file: net/core/dev.c gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb) { skb_gro_reset_offset(skb); return napi_skb_finish(dev_gro_receive(napi, skb), skb); }dev_gro_receive 这个函数代表的是⽹卡 GRO 特性,可以简单理解成把相关的⼩包合并成⼀个⼤包就⾏,⽬的是减少传送给⽹络栈的包数,这有助于减少 CPU 的使⽤量。我们暂且忽略,直接看napi_skb_finish , 这个函数主要就是调⽤了 netif_receive_skb 。//file: net/core/dev.c static gro_result_t napi_skb_finish(gro_result_t ret, struct sk_buff *skb) { switch (ret) { case GRO_NORMAL: if (netif_receive_skb(skb)) ret = GRO_DROP; break; ...... }在 netif_receive_skb 中,数据包将被送到协议栈中。3. ⽹络协议栈处理 netif_receive_skb 函数会根据包的协议,假如是 udp 包,会将包依次送到 ip_rcv(), udp_rcv() 协议处理函数中进⾏处理。//file: net/core/dev.c int netif_receive_skb(struct sk_buff *skb) { //RPS处理逻辑,先忽略 ...... return __netif_receive_skb(skb); } static int __netif_receive_skb(struct sk_buff *skb) { ...... ret = __netif_receive_skb_core(skb, false); } static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc) { ...... //pcap逻辑,这⾥会将数据送⼊抓包点。tcpdump就是从这个⼊⼝获取包的 list_for_each_entry_rcu(ptype, &ptype_all, list) { if (!ptype->dev || ptype->dev == skb->dev) { if (pt_prev) ret = deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype; } } ...... list_for_each_entry_rcu(ptype, &ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) { if (ptype->type == type && (ptype->dev == null_or_dev || ptype->dev == skb->dev || ptype->dev == orig_dev)) { if (pt_prev) ret = deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype; } } }__netif_receive_skb_core 取出 protocol,它会从数据包中取出协议信息,然后遍历注册在这个协议上的回调函数列表。//file: net/core/dev.c static inline int deliver_skb(struct sk_buff *skb, struct packet_type *pt_prev, struct net_device *orig_dev) { ...... return pt_prev->func(skb, skb->dev, pt_prev, orig_dev); }pt_prev->func 这⼀⾏就调⽤到了协议层注册的处理函数了。对于 ip 包来讲,就会进⼊到 ip_rcv(如果是arp包的话,会进⼊到arp_rcv)。4. IP 协议层处理//file: net/ipv4/ip_input.c int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev) { ...... return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, skb, dev, NULL, ip_rcv_finish); }这⾥ NF_HOOK 是⼀个钩⼦函数,当执⾏完注册的钩⼦后就会执⾏到最后⼀个参数指向的函数ip_rcv_finish 。static int ip_rcv_finish(struct sk_buff *skb) { ...... if (!skb_dst(skb)) { int err = ip_route_input_noref(skb, iph->daddr, iph->saddr, iph->tos, skb->dev); ... } ...... return dst_input(skb); }ip_route_input_noref 看到它⼜调⽤了 ip_route_input_mc 。 在 ip_route_input_mc中,函数 ip_local_deliver 被赋值给了 dst.input//file: net/ipv4/route.c static int ip_route_input_mc(struct sk_buff *skb, __be32 daddr, __be32 saddr, u8 tos, struct net_device *dev, int our) { if (our) { rth->dst.input= ip_local_deliver; rth->rt_flags |= RTCF_LOCAL; } }ip_rcv_finish 中的 return dst_input(skb)/* Input packet from network to transport. */ static inline int dst_input(struct sk_buff *skb) { return skb_dst(skb)->input(skb); }skb_dst(skb)->input 调⽤的 input ⽅法就是路由⼦系统赋的 ip_local_deliver。//file: net/ipv4/ip_input.c int ip_local_deliver(struct sk_buff *skb) { /* * Reassemble IP fragments. */ if (ip_is_fragment(ip_hdr(skb))) { if (ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER)) return 0; } return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, skb, skb->dev, NULL, ip_local_deliver_finish); } static int ip_local_deliver_finish(struct sk_buff *skb) { ...... int protocol = ip_hdr(skb)->protocol; const struct net_protocol *ipprot; ipprot = rcu_dereference(inet_protos[protocol]); if (ipprot != NULL) { ret = ipprot->handler(skb); } }net_protos 中保存着 tcp_v4_rcv() 和 udp_rcv() 的函数地址。这⾥将会根据包中的协议类型选择进⾏分发,在这⾥ skb 包将会进⼀步被派送到更上层的协议中, udp 和 tcp。{/collapse} -
![nginx listen unix socket: bind() address already in use]() nginx listen unix socket: bind() address already in use {collapse}{collapse-item label="背景" open}nginx加入监听域套接字之后,通过发送QUIT信号退出导致nginx不会清理域套接字文件,重启nginx时出现bind() address already in use复现原因:pkill -SIGQUIT nginxnginx -s quit以上两条命令都会产生SIGUQUIT信号{/collapse-item}{collapse-item label="问题原因" open}1.nginx SIGQUIT_将导致“优雅关闭”,而_SIGTERM_将导致“快速关闭”。如果将_SIGQUIT_发送到Nginx,它将留下使用_listen_指令创建的过时的UNIX域套接字文件。如果 Nginx 启动时有任何过时的 UNIX 域套接字文件,它将无法侦听套接字,因为它已经存在。但是,如果您使用 _SIGTERM,_UNIX 域套接字文件将被正确删除2.官方针对这个bug在两年前进行了修复 git fix 测试修复后版本的nginx,并未出现该情况{/collapse-item}{/collapse}
nginx listen unix socket: bind() address already in use {collapse}{collapse-item label="背景" open}nginx加入监听域套接字之后,通过发送QUIT信号退出导致nginx不会清理域套接字文件,重启nginx时出现bind() address already in use复现原因:pkill -SIGQUIT nginxnginx -s quit以上两条命令都会产生SIGUQUIT信号{/collapse-item}{collapse-item label="问题原因" open}1.nginx SIGQUIT_将导致“优雅关闭”,而_SIGTERM_将导致“快速关闭”。如果将_SIGQUIT_发送到Nginx,它将留下使用_listen_指令创建的过时的UNIX域套接字文件。如果 Nginx 启动时有任何过时的 UNIX 域套接字文件,它将无法侦听套接字,因为它已经存在。但是,如果您使用 _SIGTERM,_UNIX 域套接字文件将被正确删除2.官方针对这个bug在两年前进行了修复 git fix 测试修复后版本的nginx,并未出现该情况{/collapse-item}{/collapse} -
![Tailscale pick nearest derp]() Tailscale pick nearest derp 一、项目地址 github tailscale 二、触发探测调用执行流 定时器触发{lamp/}三、实现逻辑 tailscale动态选路逻辑主要分为动态选路策略和链路探测逻辑{collapse}{collapse-item label="1.动态选路策略" open}{lamp/}{/collapse-item}{collapse-item label="2.链路探测逻辑" open}{lamp/}{/collapse-item}{/collapse}四、代码细节分析 {collapse}{collapse-item label="1.动态选路策略" open}根据探测结果筛选出最近五分钟内所有探测任务的记录,如果出现多个探测任务出现相同的区域,则记录该区域最小延时到bestRecent的map中,从最新的探测结果中找出延时最小的区域,并记录这个区域的id作为最优区域,如果当前更改首选的 DERP,但旧的仍然可用,而新的最优延时1.5倍大于旧的延时,那就坚持用旧的区域。// addReportHistoryAndSetPreferredDERP adds r to the set of recent Reports // and mutates r.PreferredDERP to contain the best recent one. func (c *Client) addReportHistoryAndSetPreferredDERP(r *Report) { c.mu.Lock() defer c.mu.Unlock() var prevDERP int if c.last != nil { prevDERP = c.last.PreferredDERP } if c.prev == nil { c.prev = map[time.Time]*Report{} } now := c.timeNow() c.prev[now] = r c.last = r const maxAge = 5 * time.Minute // region ID => its best recent latency in last maxAge bestRecent := map[int]time.Duration{} for t, pr := range c.prev { if now.Sub(t) > maxAge { delete(c.prev, t) continue } for regionID, d := range pr.RegionLatency { if bd, ok := bestRecent[regionID]; !ok || d < bd { bestRecent[regionID] = d } } } // Then, pick which currently-alive DERP server from the // current report has the best latency over the past maxAge. var bestAny time.Duration var oldRegionCurLatency time.Duration for regionID, d := range r.RegionLatency { if regionID == prevDERP { oldRegionCurLatency = d } best := bestRecent[regionID] if r.PreferredDERP == 0 || best < bestAny { bestAny = best r.PreferredDERP = regionID } } // If we're changing our preferred DERP but the old one's still // accessible and the new one's not much better, just stick with // where we are. if prevDERP != 0 && r.PreferredDERP != prevDERP && oldRegionCurLatency != 0 && bestAny > oldRegionCurLatency/3*2 { r.PreferredDERP = prevDERP } }选出最优的区域之后,如果发现udp被block, pickDERPFallback 随机返回一个非零但确定的 DERP 节点,这仅在 netcheck 找不到最近的一个时使用(例如,如果UDP被阻止,因此 STUN 延迟检查不起作用)if ni.PreferredDERP == 0 { // Perhaps UDP is blocked. Pick a deterministic but arbitrary // one. ni.PreferredDERP = c.pickDERPFallback() } if !c.setNearestDERP(ni.PreferredDERP) { ni.PreferredDERP = 0 }判断当前选出来的最优区域和当前使用的是否相等,如果不等,将更新,更改时,遍历当前正在连接的所有 DERP 服务器,如果当前使用的derp服务器的区域不是当前优选的话,将会调用closeForReconnect 关闭底层网络连接并 将客户端字段清零,以便将来对 Connect 的调用将重新连接,区域id作为端口传给goDerpConnect(),去连接指定区域的derp服务器,按顺序选择一个可用的,可以减少同一个区域的情况下路由的消耗。func (c *Conn) setNearestDERP(derpNum int) (wantDERP bool) { c.mu.Lock() defer c.mu.Unlock() if !c.wantDerpLocked() { c.myDerp = 0 health.SetMagicSockDERPHome(0) return false } if derpNum == c.myDerp { // No change. return true } if c.myDerp != 0 && derpNum != 0 { metricDERPHomeChange.Add(1) } c.myDerp = derpNum health.SetMagicSockDERPHome(derpNum) if c.privateKey.IsZero() { // No private key yet, so DERP connections won't come up anyway. // Return early rather than ultimately log a couple lines of noise. return true } // On change, notify all currently connected DERP servers and // start connecting to our home DERP if we are not already. dr := c.derpMap.Regions[derpNum] if dr == nil { c.logf("[unexpected] magicsock: derpMap.Regions[%v] is nil", derpNum) } else { c.logf("magicsock: home is now derp-%v (%v)", derpNum, c.derpMap.Regions[derpNum].RegionCode) } for i, ad := range c.activeDerp { go ad.c.NotePreferred(i == c.myDerp) } c.goDerpConnect(derpNum) return true }{/collapse-item}{collapse-item label="2.链路探测逻辑" open}链路探测调用入口,绑定接收stun回包的函数,收到回包之后校验完之后,调用GetReport()时在启动探测任务runProbe()时设置的回调函数,来计算从设置回调函数到回复包收到之后调用回调函数的时间差作为该节点的延时func (c *Conn) updateNetInfo(ctx context.Context) (*netcheck.Report, error) { c.mu.Lock() dm := c.derpMap c.mu.Unlock() if dm == nil || c.networkDown() { return new(netcheck.Report), nil } ctx, cancel := context.WithTimeout(ctx, 2*time.Second) defer cancel() c.stunReceiveFunc.Store(c.netChecker.ReceiveSTUNPacket) defer c.ignoreSTUNPackets() report, err := c.netChecker.GetReport(ctx, dm) if err != nil { return nil, err }metricNumGetReportError 统计探测次数和metricNumGetReport探测失败的指标,对探测节点的列表进行判断,为空则不探测,为了防止探测并发执行,对curState进行校验,即使配置的下发是全量的,也会记录上一次探测选出来的最优derp区域。判断是否对所有节点都做探测时,根据上一次全量探测距离现在超过5分钟或者之前的探测被门户拦截了来决定是否要进行全量探测。func (c *Client) GetReport(ctx context.Context, dm *tailcfg.DERPMap) (_ *Report, reterr error) { defer func() { if reterr != nil { metricNumGetReportError.Add(1) //每次探测失败,探测的指标计数就会加一 } }() metricNumGetReport.Add(1) //每次探测,都会增加一次探测的计数 // Mask user context with ours that we guarantee to cancel so // we can depend on it being closed in goroutines later. // (User ctx might be context.Background, etc) ctx, cancel := context.WithTimeout(ctx, overallProbeTimeout) //保证每次探测不会超过5s defer cancel() if dm == nil { // 判断需要探测的节点列表是否为空 return nil, errors.New("netcheck: GetReport: DERP map is nil") } c.mu.Lock() if c.curState != nil { c.mu.Unlock() return nil, errors.New("invalid concurrent call to GetReport") } rs := &reportState{ c: c, report: newReport(), inFlight: map[stun.TxID]func(netip.AddrPort){}, hairTX: stun.NewTxID(), // random payload gotHairSTUN: make(chan netip.AddrPort, 1), hairTimeout: make(chan struct{}), stopProbeCh: make(chan struct{}, 1), } c.curState = rs last := c.last // Even if we're doing a non-incremental update, we may want to try our // preferred DERP region for captive portal detection. Save that, if we // have it. var preferredDERP int if last != nil { preferredDERP = last.PreferredDERP //即使是全量更新配置,仍然记录上一次探测选点的结果 } now := c.timeNow() doFull := false if c.nextFull || now.Sub(c.lastFull) > 5*time.Minute { doFull = true } // If the last report had a captive portal and reported no UDP access, // it's possible that we didn't get a useful netcheck due to the // captive portal blocking us. If so, make this report a full // (non-incremental) one. if !doFull && last != nil { doFull = !last.UDP && last.CaptivePortal.EqualBool(true) } if doFull { last = nil // causes makeProbePlan below to do a full (initial) plan c.nextFull = false c.lastFull = now metricNumGetReportFull.Add(1) } rs.incremental = last != nil c.mu.Unlock() defer func() { c.mu.Lock() defer c.mu.Unlock() c.curState = nil //每次探测完之后,将当前状态置为空 }()存储机器的网络接口、路由表和其他网络配置的状态ifState, err := interfaces.GetState() if err != nil { c.logf("[v1] interfaces: %v", err) return nil, err }检测本地环境对v4/v6的支持情况// See if IPv6 works at all, or if it's been hard disabled at the // OS level. v6udp, err := nettype.MakePacketListenerWithNetIP(netns.Listener(c.logf)).ListenPacket(ctx, "udp6", "[::1]:0") if err == nil { rs.report.OSHasIPv6 = true v6udp.Close() } // Create a UDP4 socket used for sending to our discovered IPv4 address. rs.pc4Hair, err = nettype.MakePacketListenerWithNetIP(netns.Listener(c.logf)).ListenPacket(ctx, "udp4", ":0") if err != nil { c.logf("udp4: %v", err) return nil, err } defer rs.pc4Hair.Close()如果是不测试,则SkipExternalNetwork为false,在本地默认网关设备上发起UPnP IGD、NAT-PMP 和 PCP请求。 如果其中一个协议引起响应,将请求公网端口映射。 可以将其视为一种着增强式的 stun,除了找到本机的公网ip:port映射之外,任何地方到达映射端口的任何数据包都会返回给本地。if !c.SkipExternalNetwork && c.PortMapper != nil { rs.waitPortMap.Add(1) go rs.probePortMapServices() }生成探测derpMap的任务plan := makeProbePlan(dm, ifState, last)生成探测任务的时候,根据上次探测结果来决定这次探测任务的策略func makeProbePlan(dm *tailcfg.DERPMap, ifState *interfaces.State, last *Report) (plan probePlan) { if last == nil || len(last.RegionLatency) == 0 { return makeProbePlanInitial(dm, ifState) }当上次探测的结果为空或者需要做全量探测的时候,会根据不同区域依次选出三个节点进行探测,如果有区域不足三个节点则采用轮询的方式循环三次将该区域的节点加入到探测任务中,例如:如果某个区域只有一个节点,则会生成三个对该节点探测的任务,每个节点开始执行探测任务的延迟分别是0ms,100ms,200ms.func makeProbePlanInitial(dm *tailcfg.DERPMap, ifState *interfaces.State) (plan probePlan) { plan = make(probePlan) for _, reg := range dm.Regions { var p4 []probe var p6 []probe for try := 0; try < 3; try++ { n := reg.Nodes[try%len(reg.Nodes)] delay := time.Duration(try) * defaultInitialRetransmitTime if ifState.HaveV4 && nodeMight4(n) { p4 = append(p4, probe{delay: delay, node: n.Name, proto: probeIPv4}) } if ifState.HaveV6 && nodeMight6(n) { p6 = append(p6, probe{delay: delay, node: n.Name, proto: probeIPv6}) } } if len(p4) > 0 { plan[fmt.Sprintf("region-%d-v4", reg.RegionID)] = p4 } if len(p6) > 0 { plan[fmt.Sprintf("region-%d-v6", reg.RegionID)] = p6 } } return plan }如果上次探测结果不为空,按照上次不同区域的延时从小到大排序,只探测延时最短的三个区域,如果探测的区域是上一次选出的最优区域,会将该区域探测的节点数增加到4个。每个探测任务启动的时候会设置延时为(try50ms+try上次探测该区域的延时*1.2),try表示每个区域需要探测几个节点,这个延时主要用于重试 UDP 丢包或超时。探测最快的两个区域时,分别选择两个节点探测,探测延时快慢排序第三的区域选出一个节点探测。func makeProbePlan(dm *tailcfg.DERPMap, ifState *interfaces.State, last *Report) (plan probePlan) { if last == nil || len(last.RegionLatency) == 0 { return makeProbePlanInitial(dm, ifState) } have6if := ifState.HaveV6 have4if := ifState.HaveV4 plan = make(probePlan) if !have4if && !have6if { return plan } had4 := len(last.RegionV4Latency) > 0 had6 := len(last.RegionV6Latency) > 0 hadBoth := have6if && had4 && had6 for ri, reg := range sortRegions(dm, last) { if ri == numIncrementalRegions { break } var p4, p6 []probe do4 := have4if do6 := have6if // By default, each node only gets one STUN packet sent, // except the fastest two from the previous round. tries := 1 isFastestTwo := ri < 2 if isFastestTwo { tries = 2 } else if hadBoth { // For dual stack machines, make the 3rd & slower nodes alternate // between. if ri%2 == 0 { do4, do6 = true, false } else { do4, do6 = false, true } } if !isFastestTwo && !had6 { do6 = false } if reg.RegionID == last.PreferredDERP { // But if we already had a DERP home, try extra hard to // make sure it's there so we don't flip flop around. tries = 4 } for try := 0; try < tries; try++ { if len(reg.Nodes) == 0 { // Shouldn't be possible. continue } if try != 0 && !had6 { do6 = false } n := reg.Nodes[try%len(reg.Nodes)] prevLatency := last.RegionLatency[reg.RegionID] * 120 / 100 if prevLatency == 0 { prevLatency = defaultActiveRetransmitTime } delay := time.Duration(try) * prevLatency if try > 1 { delay += time.Duration(try) * 50 * time.Millisecond } if do4 { p4 = append(p4, probe{delay: delay, node: n.Name, proto: probeIPv4}) } if do6 { p6 = append(p6, probe{delay: delay, node: n.Name, proto: probeIPv6}) } } if len(p4) > 0 { plan[fmt.Sprintf("region-%d-v4", reg.RegionID)] = p4 } if len(p6) > 0 { plan[fmt.Sprintf("region-%d-v6", reg.RegionID)] = p6 } } return plan }根据策略生成完探测任务之后,遍历所有的探测任务,开始执行任务,通过自己封装的waitGroup,等执行完探测任务之后,计数减一,当所有的探测任务goroutine结束之后通过wg.DoneChan()可以感知到wg := syncs.NewWaitGroupChan() wg.Add(len(plan)) for _, probeSet := range plan { setCtx, cancelSet := context.WithCancel(ctx) go func(probeSet []probe) { for _, probe := range probeSet { go rs.runProbe(setCtx, dm, probe, cancelSet) } <-setCtx.Done() wg.Decr() }(probeSet) } stunTimer := time.NewTimer(stunProbeTimeout) defer stunTimer.Stop() select { case <-stunTimer.C: case <-ctx.Done(): case <-wg.DoneChan(): // All of our probes finished, so if we have >0 responses, we // stop our captive portal check. if rs.anyUDP() { captivePortalStop() } case <-rs.stopProbeCh: // Saw enough regions. c.vlogf("saw enough regions; not waiting for rest") // We can stop the captive portal check since we know that we // got a bunch of STUN responses. captivePortalStop() }探测任务执行流,每个探测任务在执行之前都需要用makeProbe生成当前任务时设置的延时,定时器在这个延时后才会执行探测。封装stun的数据报发送给被探测的节点。func (rs *reportState) runProbe(ctx context.Context, dm *tailcfg.DERPMap, probe probe, cancelSet func()) { c := rs.c node := namedNode(dm, probe.node) if node == nil { c.logf("netcheck.runProbe: named node %q not found", probe.node) return } if probe.delay > 0 { delayTimer := time.NewTimer(probe.delay) select { case <-delayTimer.C: case <-ctx.Done(): delayTimer.Stop() return } } if !rs.probeWouldHelp(probe, node) { cancelSet() return } addr := c.nodeAddr(ctx, node, probe.proto) if !addr.IsValid() { return } txID := stun.NewTxID() req := stun.Request(txID) sent := time.Now() // after DNS lookup above rs.mu.Lock() rs.inFlight[txID] = func(ipp netip.AddrPort) { rs.addNodeLatency(node, ipp, time.Since(sent)) cancelSet() // abort other nodes in this set } rs.mu.Unlock() switch probe.proto { case probeIPv4: metricSTUNSend4.Add(1) n, err := rs.pc4.WriteToUDPAddrPort(req, addr) if n == len(req) && err == nil || neterror.TreatAsLostUDP(err) { rs.mu.Lock() rs.report.IPv4CanSend = true rs.mu.Unlock() } case probeIPv6: metricSTUNSend6.Add(1) n, err := rs.pc6.WriteToUDPAddrPort(req, addr) if n == len(req) && err == nil || neterror.TreatAsLostUDP(err) { rs.mu.Lock() rs.report.IPv6CanSend = true rs.mu.Unlock() } default: panic("bad probe proto " + fmt.Sprint(probe.proto)) } c.vlogf("sent to %v", addr) }尝试 HTTPS 和 ICMP 延迟检查是否所有 STUN 探测都因 UDP 可能被阻止而失败。在 HTTPS 检查的同时启动 ICMP, 不会为这些探测重用相同的 WaitGroup,需要在超时后或所有 ICMP 探测完成后关闭底层 Pinger,而不管 HTTPS 探测是否已完成。// Try HTTPS and ICMP latency check if all STUN probes failed due to // UDP presumably being blocked. // TODO: this should be moved into the probePlan, using probeProto probeHTTPS. if !rs.anyUDP() && ctx.Err() == nil { var wg sync.WaitGroup var need []*tailcfg.DERPRegion for rid, reg := range dm.Regions { if !rs.haveRegionLatency(rid) && regionHasDERPNode(reg) { need = append(need, reg) } } if len(need) > 0 { // Kick off ICMP in parallel to HTTPS checks; we don't // reuse the same WaitGroup for those probes because we // need to close the underlying Pinger after a timeout // or when all ICMP probes are done, regardless of // whether the HTTPS probes have finished. wg.Add(1) go func() { defer wg.Done() if err := c.measureAllICMPLatency(ctx, rs, need); err != nil { c.logf("[v1] measureAllICMPLatency: %v", err) } }() wg.Add(len(need)) c.logf("netcheck: UDP is blocked, trying HTTPS") } for _, reg := range need { go func(reg *tailcfg.DERPRegion) { defer wg.Done() if d, ip, err := c.measureHTTPSLatency(ctx, reg); err != nil { c.logf("[v1] netcheck: measuring HTTPS latency of %v (%d): %v", reg.RegionCode, reg.RegionID, err) } else { rs.mu.Lock() if l, ok := rs.report.RegionLatency[reg.RegionID]; !ok { mak.Set(&rs.report.RegionLatency, reg.RegionID, d) } else if l >= d { rs.report.RegionLatency[reg.RegionID] = d } // We set these IPv4 and IPv6 but they're not really used // and we don't necessarily set them both. If UDP is blocked // and both IPv4 and IPv6 are available over TCP, it's basically // random which fields end up getting set here. // Since they're not needed, that's fine for now. if ip.Is4() { rs.report.IPv4 = true } if ip.Is6() { rs.report.IPv6 = true } rs.mu.Unlock() } }(reg) } wg.Wait() }完成探测并记录探测数据,并选出最优的区域func (c *Client) finishAndStoreReport(rs *reportState, dm *tailcfg.DERPMap) *Report { rs.mu.Lock() report := rs.report.Clone() rs.mu.Unlock() c.addReportHistoryAndSetPreferredDERP(report) c.logConciseReport(report, dm) return report }{/collapse-item}{/collapse}
Tailscale pick nearest derp 一、项目地址 github tailscale 二、触发探测调用执行流 定时器触发{lamp/}三、实现逻辑 tailscale动态选路逻辑主要分为动态选路策略和链路探测逻辑{collapse}{collapse-item label="1.动态选路策略" open}{lamp/}{/collapse-item}{collapse-item label="2.链路探测逻辑" open}{lamp/}{/collapse-item}{/collapse}四、代码细节分析 {collapse}{collapse-item label="1.动态选路策略" open}根据探测结果筛选出最近五分钟内所有探测任务的记录,如果出现多个探测任务出现相同的区域,则记录该区域最小延时到bestRecent的map中,从最新的探测结果中找出延时最小的区域,并记录这个区域的id作为最优区域,如果当前更改首选的 DERP,但旧的仍然可用,而新的最优延时1.5倍大于旧的延时,那就坚持用旧的区域。// addReportHistoryAndSetPreferredDERP adds r to the set of recent Reports // and mutates r.PreferredDERP to contain the best recent one. func (c *Client) addReportHistoryAndSetPreferredDERP(r *Report) { c.mu.Lock() defer c.mu.Unlock() var prevDERP int if c.last != nil { prevDERP = c.last.PreferredDERP } if c.prev == nil { c.prev = map[time.Time]*Report{} } now := c.timeNow() c.prev[now] = r c.last = r const maxAge = 5 * time.Minute // region ID => its best recent latency in last maxAge bestRecent := map[int]time.Duration{} for t, pr := range c.prev { if now.Sub(t) > maxAge { delete(c.prev, t) continue } for regionID, d := range pr.RegionLatency { if bd, ok := bestRecent[regionID]; !ok || d < bd { bestRecent[regionID] = d } } } // Then, pick which currently-alive DERP server from the // current report has the best latency over the past maxAge. var bestAny time.Duration var oldRegionCurLatency time.Duration for regionID, d := range r.RegionLatency { if regionID == prevDERP { oldRegionCurLatency = d } best := bestRecent[regionID] if r.PreferredDERP == 0 || best < bestAny { bestAny = best r.PreferredDERP = regionID } } // If we're changing our preferred DERP but the old one's still // accessible and the new one's not much better, just stick with // where we are. if prevDERP != 0 && r.PreferredDERP != prevDERP && oldRegionCurLatency != 0 && bestAny > oldRegionCurLatency/3*2 { r.PreferredDERP = prevDERP } }选出最优的区域之后,如果发现udp被block, pickDERPFallback 随机返回一个非零但确定的 DERP 节点,这仅在 netcheck 找不到最近的一个时使用(例如,如果UDP被阻止,因此 STUN 延迟检查不起作用)if ni.PreferredDERP == 0 { // Perhaps UDP is blocked. Pick a deterministic but arbitrary // one. ni.PreferredDERP = c.pickDERPFallback() } if !c.setNearestDERP(ni.PreferredDERP) { ni.PreferredDERP = 0 }判断当前选出来的最优区域和当前使用的是否相等,如果不等,将更新,更改时,遍历当前正在连接的所有 DERP 服务器,如果当前使用的derp服务器的区域不是当前优选的话,将会调用closeForReconnect 关闭底层网络连接并 将客户端字段清零,以便将来对 Connect 的调用将重新连接,区域id作为端口传给goDerpConnect(),去连接指定区域的derp服务器,按顺序选择一个可用的,可以减少同一个区域的情况下路由的消耗。func (c *Conn) setNearestDERP(derpNum int) (wantDERP bool) { c.mu.Lock() defer c.mu.Unlock() if !c.wantDerpLocked() { c.myDerp = 0 health.SetMagicSockDERPHome(0) return false } if derpNum == c.myDerp { // No change. return true } if c.myDerp != 0 && derpNum != 0 { metricDERPHomeChange.Add(1) } c.myDerp = derpNum health.SetMagicSockDERPHome(derpNum) if c.privateKey.IsZero() { // No private key yet, so DERP connections won't come up anyway. // Return early rather than ultimately log a couple lines of noise. return true } // On change, notify all currently connected DERP servers and // start connecting to our home DERP if we are not already. dr := c.derpMap.Regions[derpNum] if dr == nil { c.logf("[unexpected] magicsock: derpMap.Regions[%v] is nil", derpNum) } else { c.logf("magicsock: home is now derp-%v (%v)", derpNum, c.derpMap.Regions[derpNum].RegionCode) } for i, ad := range c.activeDerp { go ad.c.NotePreferred(i == c.myDerp) } c.goDerpConnect(derpNum) return true }{/collapse-item}{collapse-item label="2.链路探测逻辑" open}链路探测调用入口,绑定接收stun回包的函数,收到回包之后校验完之后,调用GetReport()时在启动探测任务runProbe()时设置的回调函数,来计算从设置回调函数到回复包收到之后调用回调函数的时间差作为该节点的延时func (c *Conn) updateNetInfo(ctx context.Context) (*netcheck.Report, error) { c.mu.Lock() dm := c.derpMap c.mu.Unlock() if dm == nil || c.networkDown() { return new(netcheck.Report), nil } ctx, cancel := context.WithTimeout(ctx, 2*time.Second) defer cancel() c.stunReceiveFunc.Store(c.netChecker.ReceiveSTUNPacket) defer c.ignoreSTUNPackets() report, err := c.netChecker.GetReport(ctx, dm) if err != nil { return nil, err }metricNumGetReportError 统计探测次数和metricNumGetReport探测失败的指标,对探测节点的列表进行判断,为空则不探测,为了防止探测并发执行,对curState进行校验,即使配置的下发是全量的,也会记录上一次探测选出来的最优derp区域。判断是否对所有节点都做探测时,根据上一次全量探测距离现在超过5分钟或者之前的探测被门户拦截了来决定是否要进行全量探测。func (c *Client) GetReport(ctx context.Context, dm *tailcfg.DERPMap) (_ *Report, reterr error) { defer func() { if reterr != nil { metricNumGetReportError.Add(1) //每次探测失败,探测的指标计数就会加一 } }() metricNumGetReport.Add(1) //每次探测,都会增加一次探测的计数 // Mask user context with ours that we guarantee to cancel so // we can depend on it being closed in goroutines later. // (User ctx might be context.Background, etc) ctx, cancel := context.WithTimeout(ctx, overallProbeTimeout) //保证每次探测不会超过5s defer cancel() if dm == nil { // 判断需要探测的节点列表是否为空 return nil, errors.New("netcheck: GetReport: DERP map is nil") } c.mu.Lock() if c.curState != nil { c.mu.Unlock() return nil, errors.New("invalid concurrent call to GetReport") } rs := &reportState{ c: c, report: newReport(), inFlight: map[stun.TxID]func(netip.AddrPort){}, hairTX: stun.NewTxID(), // random payload gotHairSTUN: make(chan netip.AddrPort, 1), hairTimeout: make(chan struct{}), stopProbeCh: make(chan struct{}, 1), } c.curState = rs last := c.last // Even if we're doing a non-incremental update, we may want to try our // preferred DERP region for captive portal detection. Save that, if we // have it. var preferredDERP int if last != nil { preferredDERP = last.PreferredDERP //即使是全量更新配置,仍然记录上一次探测选点的结果 } now := c.timeNow() doFull := false if c.nextFull || now.Sub(c.lastFull) > 5*time.Minute { doFull = true } // If the last report had a captive portal and reported no UDP access, // it's possible that we didn't get a useful netcheck due to the // captive portal blocking us. If so, make this report a full // (non-incremental) one. if !doFull && last != nil { doFull = !last.UDP && last.CaptivePortal.EqualBool(true) } if doFull { last = nil // causes makeProbePlan below to do a full (initial) plan c.nextFull = false c.lastFull = now metricNumGetReportFull.Add(1) } rs.incremental = last != nil c.mu.Unlock() defer func() { c.mu.Lock() defer c.mu.Unlock() c.curState = nil //每次探测完之后,将当前状态置为空 }()存储机器的网络接口、路由表和其他网络配置的状态ifState, err := interfaces.GetState() if err != nil { c.logf("[v1] interfaces: %v", err) return nil, err }检测本地环境对v4/v6的支持情况// See if IPv6 works at all, or if it's been hard disabled at the // OS level. v6udp, err := nettype.MakePacketListenerWithNetIP(netns.Listener(c.logf)).ListenPacket(ctx, "udp6", "[::1]:0") if err == nil { rs.report.OSHasIPv6 = true v6udp.Close() } // Create a UDP4 socket used for sending to our discovered IPv4 address. rs.pc4Hair, err = nettype.MakePacketListenerWithNetIP(netns.Listener(c.logf)).ListenPacket(ctx, "udp4", ":0") if err != nil { c.logf("udp4: %v", err) return nil, err } defer rs.pc4Hair.Close()如果是不测试,则SkipExternalNetwork为false,在本地默认网关设备上发起UPnP IGD、NAT-PMP 和 PCP请求。 如果其中一个协议引起响应,将请求公网端口映射。 可以将其视为一种着增强式的 stun,除了找到本机的公网ip:port映射之外,任何地方到达映射端口的任何数据包都会返回给本地。if !c.SkipExternalNetwork && c.PortMapper != nil { rs.waitPortMap.Add(1) go rs.probePortMapServices() }生成探测derpMap的任务plan := makeProbePlan(dm, ifState, last)生成探测任务的时候,根据上次探测结果来决定这次探测任务的策略func makeProbePlan(dm *tailcfg.DERPMap, ifState *interfaces.State, last *Report) (plan probePlan) { if last == nil || len(last.RegionLatency) == 0 { return makeProbePlanInitial(dm, ifState) }当上次探测的结果为空或者需要做全量探测的时候,会根据不同区域依次选出三个节点进行探测,如果有区域不足三个节点则采用轮询的方式循环三次将该区域的节点加入到探测任务中,例如:如果某个区域只有一个节点,则会生成三个对该节点探测的任务,每个节点开始执行探测任务的延迟分别是0ms,100ms,200ms.func makeProbePlanInitial(dm *tailcfg.DERPMap, ifState *interfaces.State) (plan probePlan) { plan = make(probePlan) for _, reg := range dm.Regions { var p4 []probe var p6 []probe for try := 0; try < 3; try++ { n := reg.Nodes[try%len(reg.Nodes)] delay := time.Duration(try) * defaultInitialRetransmitTime if ifState.HaveV4 && nodeMight4(n) { p4 = append(p4, probe{delay: delay, node: n.Name, proto: probeIPv4}) } if ifState.HaveV6 && nodeMight6(n) { p6 = append(p6, probe{delay: delay, node: n.Name, proto: probeIPv6}) } } if len(p4) > 0 { plan[fmt.Sprintf("region-%d-v4", reg.RegionID)] = p4 } if len(p6) > 0 { plan[fmt.Sprintf("region-%d-v6", reg.RegionID)] = p6 } } return plan }如果上次探测结果不为空,按照上次不同区域的延时从小到大排序,只探测延时最短的三个区域,如果探测的区域是上一次选出的最优区域,会将该区域探测的节点数增加到4个。每个探测任务启动的时候会设置延时为(try50ms+try上次探测该区域的延时*1.2),try表示每个区域需要探测几个节点,这个延时主要用于重试 UDP 丢包或超时。探测最快的两个区域时,分别选择两个节点探测,探测延时快慢排序第三的区域选出一个节点探测。func makeProbePlan(dm *tailcfg.DERPMap, ifState *interfaces.State, last *Report) (plan probePlan) { if last == nil || len(last.RegionLatency) == 0 { return makeProbePlanInitial(dm, ifState) } have6if := ifState.HaveV6 have4if := ifState.HaveV4 plan = make(probePlan) if !have4if && !have6if { return plan } had4 := len(last.RegionV4Latency) > 0 had6 := len(last.RegionV6Latency) > 0 hadBoth := have6if && had4 && had6 for ri, reg := range sortRegions(dm, last) { if ri == numIncrementalRegions { break } var p4, p6 []probe do4 := have4if do6 := have6if // By default, each node only gets one STUN packet sent, // except the fastest two from the previous round. tries := 1 isFastestTwo := ri < 2 if isFastestTwo { tries = 2 } else if hadBoth { // For dual stack machines, make the 3rd & slower nodes alternate // between. if ri%2 == 0 { do4, do6 = true, false } else { do4, do6 = false, true } } if !isFastestTwo && !had6 { do6 = false } if reg.RegionID == last.PreferredDERP { // But if we already had a DERP home, try extra hard to // make sure it's there so we don't flip flop around. tries = 4 } for try := 0; try < tries; try++ { if len(reg.Nodes) == 0 { // Shouldn't be possible. continue } if try != 0 && !had6 { do6 = false } n := reg.Nodes[try%len(reg.Nodes)] prevLatency := last.RegionLatency[reg.RegionID] * 120 / 100 if prevLatency == 0 { prevLatency = defaultActiveRetransmitTime } delay := time.Duration(try) * prevLatency if try > 1 { delay += time.Duration(try) * 50 * time.Millisecond } if do4 { p4 = append(p4, probe{delay: delay, node: n.Name, proto: probeIPv4}) } if do6 { p6 = append(p6, probe{delay: delay, node: n.Name, proto: probeIPv6}) } } if len(p4) > 0 { plan[fmt.Sprintf("region-%d-v4", reg.RegionID)] = p4 } if len(p6) > 0 { plan[fmt.Sprintf("region-%d-v6", reg.RegionID)] = p6 } } return plan }根据策略生成完探测任务之后,遍历所有的探测任务,开始执行任务,通过自己封装的waitGroup,等执行完探测任务之后,计数减一,当所有的探测任务goroutine结束之后通过wg.DoneChan()可以感知到wg := syncs.NewWaitGroupChan() wg.Add(len(plan)) for _, probeSet := range plan { setCtx, cancelSet := context.WithCancel(ctx) go func(probeSet []probe) { for _, probe := range probeSet { go rs.runProbe(setCtx, dm, probe, cancelSet) } <-setCtx.Done() wg.Decr() }(probeSet) } stunTimer := time.NewTimer(stunProbeTimeout) defer stunTimer.Stop() select { case <-stunTimer.C: case <-ctx.Done(): case <-wg.DoneChan(): // All of our probes finished, so if we have >0 responses, we // stop our captive portal check. if rs.anyUDP() { captivePortalStop() } case <-rs.stopProbeCh: // Saw enough regions. c.vlogf("saw enough regions; not waiting for rest") // We can stop the captive portal check since we know that we // got a bunch of STUN responses. captivePortalStop() }探测任务执行流,每个探测任务在执行之前都需要用makeProbe生成当前任务时设置的延时,定时器在这个延时后才会执行探测。封装stun的数据报发送给被探测的节点。func (rs *reportState) runProbe(ctx context.Context, dm *tailcfg.DERPMap, probe probe, cancelSet func()) { c := rs.c node := namedNode(dm, probe.node) if node == nil { c.logf("netcheck.runProbe: named node %q not found", probe.node) return } if probe.delay > 0 { delayTimer := time.NewTimer(probe.delay) select { case <-delayTimer.C: case <-ctx.Done(): delayTimer.Stop() return } } if !rs.probeWouldHelp(probe, node) { cancelSet() return } addr := c.nodeAddr(ctx, node, probe.proto) if !addr.IsValid() { return } txID := stun.NewTxID() req := stun.Request(txID) sent := time.Now() // after DNS lookup above rs.mu.Lock() rs.inFlight[txID] = func(ipp netip.AddrPort) { rs.addNodeLatency(node, ipp, time.Since(sent)) cancelSet() // abort other nodes in this set } rs.mu.Unlock() switch probe.proto { case probeIPv4: metricSTUNSend4.Add(1) n, err := rs.pc4.WriteToUDPAddrPort(req, addr) if n == len(req) && err == nil || neterror.TreatAsLostUDP(err) { rs.mu.Lock() rs.report.IPv4CanSend = true rs.mu.Unlock() } case probeIPv6: metricSTUNSend6.Add(1) n, err := rs.pc6.WriteToUDPAddrPort(req, addr) if n == len(req) && err == nil || neterror.TreatAsLostUDP(err) { rs.mu.Lock() rs.report.IPv6CanSend = true rs.mu.Unlock() } default: panic("bad probe proto " + fmt.Sprint(probe.proto)) } c.vlogf("sent to %v", addr) }尝试 HTTPS 和 ICMP 延迟检查是否所有 STUN 探测都因 UDP 可能被阻止而失败。在 HTTPS 检查的同时启动 ICMP, 不会为这些探测重用相同的 WaitGroup,需要在超时后或所有 ICMP 探测完成后关闭底层 Pinger,而不管 HTTPS 探测是否已完成。// Try HTTPS and ICMP latency check if all STUN probes failed due to // UDP presumably being blocked. // TODO: this should be moved into the probePlan, using probeProto probeHTTPS. if !rs.anyUDP() && ctx.Err() == nil { var wg sync.WaitGroup var need []*tailcfg.DERPRegion for rid, reg := range dm.Regions { if !rs.haveRegionLatency(rid) && regionHasDERPNode(reg) { need = append(need, reg) } } if len(need) > 0 { // Kick off ICMP in parallel to HTTPS checks; we don't // reuse the same WaitGroup for those probes because we // need to close the underlying Pinger after a timeout // or when all ICMP probes are done, regardless of // whether the HTTPS probes have finished. wg.Add(1) go func() { defer wg.Done() if err := c.measureAllICMPLatency(ctx, rs, need); err != nil { c.logf("[v1] measureAllICMPLatency: %v", err) } }() wg.Add(len(need)) c.logf("netcheck: UDP is blocked, trying HTTPS") } for _, reg := range need { go func(reg *tailcfg.DERPRegion) { defer wg.Done() if d, ip, err := c.measureHTTPSLatency(ctx, reg); err != nil { c.logf("[v1] netcheck: measuring HTTPS latency of %v (%d): %v", reg.RegionCode, reg.RegionID, err) } else { rs.mu.Lock() if l, ok := rs.report.RegionLatency[reg.RegionID]; !ok { mak.Set(&rs.report.RegionLatency, reg.RegionID, d) } else if l >= d { rs.report.RegionLatency[reg.RegionID] = d } // We set these IPv4 and IPv6 but they're not really used // and we don't necessarily set them both. If UDP is blocked // and both IPv4 and IPv6 are available over TCP, it's basically // random which fields end up getting set here. // Since they're not needed, that's fine for now. if ip.Is4() { rs.report.IPv4 = true } if ip.Is6() { rs.report.IPv6 = true } rs.mu.Unlock() } }(reg) } wg.Wait() }完成探测并记录探测数据,并选出最优的区域func (c *Client) finishAndStoreReport(rs *reportState, dm *tailcfg.DERPMap) *Report { rs.mu.Lock() report := rs.report.Clone() rs.mu.Unlock() c.addReportHistoryAndSetPreferredDERP(report) c.logConciseReport(report, dm) return report }{/collapse-item}{/collapse} -
![Libcurl HTTP]() Libcurl HTTP 关于libcurl的相关函数介绍以及参数详见官方说明 curl HTTP Request 一个http请求包含方法、路径、http版本、请求包头请求方法 GET, HEAD, POST, PUT, DELETE, PATCH, OPTIONSGETcurl_easy_setopt(curl, CURLOPT_URL, "http://example.com?id=1")POSTcurl_easy_setopt(curl, CURLOPT_URL, "http://example.com"); curl_easy_setopt(curl, CURLOPT_POSTFIELDS, "username=admin&password=123");PUTcurl_easy_setopt(curl, CURLOPT_UPLOAD, 1L);DELETEcurl_easy_setopt(curl, CURLOPT_CUSTOMREQUEST, "DELETE"); curl_easy_setopt(curl, CURLOPT_URL, "https://example.com/file.txt");libcurl HTTP 请求包头 默认不设置的包头GET /file1.txt HTTP/1.1 Host: localhost Accept: */*POST /file1.txt HTTP/1.1 Host: localhost Accept: */* Content-Length: 6 Content-Type: application/x-www-form-urlencoded设置自定义包头添加一个包头 Name:Mikestruct curl_slist *list = NULL; list = curl_slist_append(list, "Name: Mike"); curl_easy_setopt(curl, CURLOPT_HTTPHEADER, list); curl_easy_perform(curl); curl_slist_free_all(list); /* free the list again */修改一个包头 Host: Alternativestruct curl_slist *list = NULL; list = curl_slist_append(list, "Host: Alternative"); curl_easy_setopt(curl, CURLOPT_HTTPHEADER, list); curl_easy_perform(curl); curl_slist_free_all(list); /* free the list again */删除一个包头struct curl_slist *list = NULL; list = curl_slist_append(list, "Accept:"); curl_easy_setopt(curl, CURLOPT_HTTPHEADER, list); curl_easy_perform(curl); curl_slist_free_all(list); /* free the list again */提供一个没有内容的包头struct curl_slist *list = NULL; list = curl_slist_append(list, "Moo;"); curl_easy_setopt(curl, CURLOPT_HTTPHEADER, list); curl_easy_perform(curl); curl_slist_free_all(list); /* free the list again */HTTP Response HTTP response code常见HTTP响应码Code Meaning1xx Transient code, a new one follows2xx Things are OK3xx The content is somewhere else4xx Failed because of a client problem5xx Failed because of a server problem获取相应状态码long code;curl_easy_getinfo(curl, CURLINFO_RESPONSE_CODE, &code);除了check curl请求的状态 check服务端返回过来的response statusCodeHTTP Range 如果客户端只希望从远程资源中获得前200个字节,或者在中间某个地方需要300个字节时//只取前两百个字节 curl_easy_setopt(curl, CURLOPT_RANGE, "0-199"); //从索引200开始的文件中的所有内容 curl_easy_setopt(curl, CURLOPT_RANGE, "200-"); //从索引0获取200字节,从索引1000获取200字节 curl_easy_setopt(curl, CURLOPT_RANGE, "0-199,1000-199");HTTP Authentication 用户名密码验证curl_easy_setopt(curl, CURLOPT_USERNAME, "joe"); curl_easy_setopt(curl, CURLOPT_PASSWORD, "secret");验证请求客户端并不能决定发送一个验证请求,当服务有资源需要被保护并且需要请求验证,服务器将会返回一个401和WWW-Authenticate: header,这个header包含了特定的验证方式curl_easy_setopt(curl, CURLOPT_HTTPAUTH, CURLAUTH_BASIC); curl_easy_setopt(curl, CURLOPT_HTTPAUTH, CURLAUTH_DIGEST); curl_easy_setopt(curl, CURLOPT_HTTPAUTH, CURLAUTH_NTLM); curl_easy_setopt(curl, CURLOPT_HTTPAUTH, CURLAUTH_NEGOTIATE);Cookie with libcurl cookie验证当启用cookie engine时 cookie将存储在相关联的句柄内存中读取cookiecurl_easy_setopt(easy, CURLOPT_COOKIEFILE, "cookies.txt");从服务端获取cookie并保存curl_easy_setopt(easy, CURLOPT_COOKIEJAR, "cookies.txt");稍后使用curl_easy_cleanup()关闭easy句柄时,所有已知的cookie将被写入给定文件。该文件格式是浏览器曾经使用过的众所周知的“ Netscape cookie文件”格式。设置自定义cookie 不激活cookie enginecurl_easy_setopt(easy, CURLOPT_COOKIE, "name=daniel; present=yes;");在其中设置的字符串是将在HTTP请求中发送的原始字符串,并且应采用NAME = VALUE重复序列的格式; 包括分号分隔符cookie内存区存储大量cookieAdd a cookie to the cookie store#define SEP "\\t" /* Tab separates the fields */ char *my_cookie = "example.com" /* Hostname */ SEP "FALSE" /* Include subdomains */ SEP "/" /* Path */ SEP "FALSE" /* Secure */ SEP "0" /* Expiry in epoch time format. 0 == Session */ SEP "foo" /* Name */ SEP "bar"; /* Value */ curl_easy_setopt(curl, CURLOPT_COOKIELIST, my_cookie);Get all cookies from the cookie storestruct curl_slist *cookies curl_easy_getinfo(easy, CURLINFO_COOKIELIST, &cookies); /*这将返回指向cookie的链接列表的指针,并且每个cookie(再次)被指定为cookie文件格式的一行。该列表已分配给您,因此在应用程序处理完该信息后,请不要忘记调用curl_slist_free_all*/Cookie store commands//清除整个内存记录 curl_easy_setopt(curl, CURLOPT_COOKIELIST, "ALL"); //从内存中删除所有会话cookie(无有效期的cookie) curl_easy_setopt(curl, CURLOPT_COOKIELIST, "SESS"); //强制将所有cookie写入先前使用CURLOPT_COOKIEJAR指定的文件名 curl_easy_setopt(curl, CURLOPT_COOKIELIST, "FLUSH"); //从先前用CURLOPT_COOKIEFILE指定的文件名强制重新加载cookie curl_easy_setopt(curl, CURLOPT_COOKIELIST, "RELOAD"); DownloadGET方法请求资源easy = curl_easy_init(); curl_easy_setopt(easy, CURLOPT_URL, "http://example.com/"); curl_easy_perform(easy);如果使用其他方法请求资源向切随后换回get请求curl_easy_setopt(easy, CURLOPT_HTTPGET, 1L);下载相应的返回包头数据 用CURLOPT_HEADEReasy = curl_easy_init(); curl_easy_setopt(easy, CURLOPT_HEADER, 1L); curl_easy_setopt(easy, CURLOPT_URL, "http://example.com/"); curl_easy_perform(easy);或者将包头数据存储到文件easy = curl_easy_init(); FILE *file = fopen("headers", "wb"); curl_easy_setopt(easy, CURLOPT_HEADERDATA, file); curl_easy_setopt(easy, CURLOPT_URL, "http://example.com/"); curl_easy_perform(easy); fclose(file);在开发时设置详细模式,将同时显示发送到stderr的传出和传入标头:curl_easy_setopt(easy, CURLOPT_VERBOSE, 1L);获取一个页面存储到内存#include <stdio.h> #include <stdlib.h> #include <string.h> #include <curl/curl.h> struct MemoryStruct { char *memory; size_t size; }; static size_t WriteMemoryCallback(void *contents, size_t size, size_t nmemb, void *userp) { size_t realsize = size * nmemb; struct MemoryStruct *mem = (struct MemoryStruct *)userp; mem->memory = (char*)realloc(mem->memory, mem->size + realsize + 1); if(mem->memory == NULL) { return 0; } memcpy(&(mem->memory[mem->size]), contents, realsize); mem->size += realsize; mem->memory[mem->size] = 0; return realsize; } int main(void) { CURL *curl_handle; CURLcode res; struct MemoryStruct chunk; chunk.memory = malloc(1); chunk.size = 0; curl_global_init(CURL_GLOBAL_ALL); //整个程序全局只需要初始化一次 多次初始化会出问题 curl_handle = curl_easy_init(); curl_easy_setopt(curl_handle, CURLOPT_URL, "https://www.example.com/"); curl_easy_setopt(curl_handle, CURLOPT_WRITEFUNCTION, WriteMemoryCallback); curl_easy_setopt(curl_handle, CURLOPT_WRITEDATA, (void *)&chunk); //curl_easy_setopt(curl_handle, CURLOPT_USERAGENT, "libcurl-agent/1.0"); res = curl_easy_perform(curl_handle); if(res != CURLE_OK) { fprintf(stderr, "curl_easy_perform() failed: %s\n", curl_easy_strerror(res)); } else { printf("%lu bytes retrieved\n", (long)chunk.size); } curl_easy_cleanup(curl_handle); free(chunk.memory); curl_global_cleanup(); return 0; }获取一个文件流的回调函数//下载文件 static size_t Writeback(void* pBuffer, size_t nSize, size_t nMemByte, void* pParam) { //把下载到的数据以追加的方式写入文件(一定要有a,否则前面写入的内容就会被覆盖了) FILE* fp = NULL; fopen_s(&fp, "E:\\test_1.wav", "ab+"); size_t nWrite = fwrite(pBuffer, nSize, nMemByte, fp); fclose(fp); return nWrite; } //如果未设置此回调,则默认情况下libcurl使用'fwriteUploadloadhttp postHTTP请求将数据传递到服务器的标准方法,使用libcurl,通常可以提供该数据作为指针和长度curl_easy_setopt(easy, CURLOPT_POSTFIELDS, dataptr); curl_easy_setopt(easy, CURLOPT_POSTFIELDSIZE, (long)datalength);使用自定义回调函数将不断调用回调函数,直到所有数据都传输或者传输失败 如果未设置此回调,则默认情况下libcurl使用'fread'#include <stdio.h> #include <fcntl.h> #include <sys/stat.h> #include <curl/curl.h> //回调函数的签名 必须按照这个签名实现自己的回调函数 static size_t read_callback(void *ptr, size_t size, size_t nmemb, void *stream) { size_t retcode; curl_off_t nread; retcode = fread(ptr, size, nmemb, stream); nread = (curl_off_t)retcode; fprintf(stderr, "*** We read %" CURL_FORMAT_CURL_OFF_T " bytes from file\n", nread); return retcode; } int main(int argc, char **argv) { CURL *curl; CURLcode res; FILE * hd_src; struct stat file_info; char *file; char *url; if(argc < 3) return 1; file = argv[1]; url = argv[2]; stat(file, &file_info); hd_src = fopen(file, "rb"); curl_global_init(CURL_GLOBAL_ALL); curl = curl_easy_init(); if(curl) { /* we want to use our own read function */ curl_easy_setopt(curl, CURLOPT_READFUNCTION, read_callback); /* enable uploading */ curl_easy_setopt(curl, CURLOPT_UPLOAD, 1L); /* HTTP PUT please */ curl_easy_setopt(curl, CURLOPT_PUT, 1L); /* specify target URL, and note that this URL should include a file name, not only a directory */ curl_easy_setopt(curl, CURLOPT_URL, url); /* now specify which file to upload */ curl_easy_setopt(curl, CURLOPT_READDATA, hd_src); /* provide the size of the upload, we specicially typecast the value to curl_off_t since we must be sure to use the correct data size */ curl_easy_setopt(curl, CURLOPT_INFILESIZE_LARGE, (curl_off_t)file_info.st_size); /* Now run off and do what you've been told! */ res = curl_easy_perform(curl); /* Check for errors */ if(res != CURLE_OK) fprintf(stderr, "curl_easy_perform() failed: %s\n", curl_easy_strerror(res)); /* always cleanup */ curl_easy_cleanup(curl); } fclose(hd_src); /* close the local file */ curl_global_cleanup(); return 0; }HTTP PUT CURLOPT_INFILESIZE_LARGE设置上传的大小curl_easy_setopt(easy, CURLOPT_UPLOAD, 1L); curl_easy_setopt(easy, CURLOPT_INFILESIZE_LARGE, (curl_off_t) size); curl_easy_setopt(easy, CURLOPT_READFUNCTION, read_callback); curl_easy_setopt(easy, CURLOPT_URL, "https://example.com/handle/put"); /*如果不知道在传输之前不知道传输的大小,对于HTTP 1.0,您必须事先提供大小,HTTP 1.1 你可以添加 标头 Transfer-Encoding: chunked 对于HTTP 2及更高版本,则既不需要大小也不需要额外的标头*/
Libcurl HTTP 关于libcurl的相关函数介绍以及参数详见官方说明 curl HTTP Request 一个http请求包含方法、路径、http版本、请求包头请求方法 GET, HEAD, POST, PUT, DELETE, PATCH, OPTIONSGETcurl_easy_setopt(curl, CURLOPT_URL, "http://example.com?id=1")POSTcurl_easy_setopt(curl, CURLOPT_URL, "http://example.com"); curl_easy_setopt(curl, CURLOPT_POSTFIELDS, "username=admin&password=123");PUTcurl_easy_setopt(curl, CURLOPT_UPLOAD, 1L);DELETEcurl_easy_setopt(curl, CURLOPT_CUSTOMREQUEST, "DELETE"); curl_easy_setopt(curl, CURLOPT_URL, "https://example.com/file.txt");libcurl HTTP 请求包头 默认不设置的包头GET /file1.txt HTTP/1.1 Host: localhost Accept: */*POST /file1.txt HTTP/1.1 Host: localhost Accept: */* Content-Length: 6 Content-Type: application/x-www-form-urlencoded设置自定义包头添加一个包头 Name:Mikestruct curl_slist *list = NULL; list = curl_slist_append(list, "Name: Mike"); curl_easy_setopt(curl, CURLOPT_HTTPHEADER, list); curl_easy_perform(curl); curl_slist_free_all(list); /* free the list again */修改一个包头 Host: Alternativestruct curl_slist *list = NULL; list = curl_slist_append(list, "Host: Alternative"); curl_easy_setopt(curl, CURLOPT_HTTPHEADER, list); curl_easy_perform(curl); curl_slist_free_all(list); /* free the list again */删除一个包头struct curl_slist *list = NULL; list = curl_slist_append(list, "Accept:"); curl_easy_setopt(curl, CURLOPT_HTTPHEADER, list); curl_easy_perform(curl); curl_slist_free_all(list); /* free the list again */提供一个没有内容的包头struct curl_slist *list = NULL; list = curl_slist_append(list, "Moo;"); curl_easy_setopt(curl, CURLOPT_HTTPHEADER, list); curl_easy_perform(curl); curl_slist_free_all(list); /* free the list again */HTTP Response HTTP response code常见HTTP响应码Code Meaning1xx Transient code, a new one follows2xx Things are OK3xx The content is somewhere else4xx Failed because of a client problem5xx Failed because of a server problem获取相应状态码long code;curl_easy_getinfo(curl, CURLINFO_RESPONSE_CODE, &code);除了check curl请求的状态 check服务端返回过来的response statusCodeHTTP Range 如果客户端只希望从远程资源中获得前200个字节,或者在中间某个地方需要300个字节时//只取前两百个字节 curl_easy_setopt(curl, CURLOPT_RANGE, "0-199"); //从索引200开始的文件中的所有内容 curl_easy_setopt(curl, CURLOPT_RANGE, "200-"); //从索引0获取200字节,从索引1000获取200字节 curl_easy_setopt(curl, CURLOPT_RANGE, "0-199,1000-199");HTTP Authentication 用户名密码验证curl_easy_setopt(curl, CURLOPT_USERNAME, "joe"); curl_easy_setopt(curl, CURLOPT_PASSWORD, "secret");验证请求客户端并不能决定发送一个验证请求,当服务有资源需要被保护并且需要请求验证,服务器将会返回一个401和WWW-Authenticate: header,这个header包含了特定的验证方式curl_easy_setopt(curl, CURLOPT_HTTPAUTH, CURLAUTH_BASIC); curl_easy_setopt(curl, CURLOPT_HTTPAUTH, CURLAUTH_DIGEST); curl_easy_setopt(curl, CURLOPT_HTTPAUTH, CURLAUTH_NTLM); curl_easy_setopt(curl, CURLOPT_HTTPAUTH, CURLAUTH_NEGOTIATE);Cookie with libcurl cookie验证当启用cookie engine时 cookie将存储在相关联的句柄内存中读取cookiecurl_easy_setopt(easy, CURLOPT_COOKIEFILE, "cookies.txt");从服务端获取cookie并保存curl_easy_setopt(easy, CURLOPT_COOKIEJAR, "cookies.txt");稍后使用curl_easy_cleanup()关闭easy句柄时,所有已知的cookie将被写入给定文件。该文件格式是浏览器曾经使用过的众所周知的“ Netscape cookie文件”格式。设置自定义cookie 不激活cookie enginecurl_easy_setopt(easy, CURLOPT_COOKIE, "name=daniel; present=yes;");在其中设置的字符串是将在HTTP请求中发送的原始字符串,并且应采用NAME = VALUE重复序列的格式; 包括分号分隔符cookie内存区存储大量cookieAdd a cookie to the cookie store#define SEP "\\t" /* Tab separates the fields */ char *my_cookie = "example.com" /* Hostname */ SEP "FALSE" /* Include subdomains */ SEP "/" /* Path */ SEP "FALSE" /* Secure */ SEP "0" /* Expiry in epoch time format. 0 == Session */ SEP "foo" /* Name */ SEP "bar"; /* Value */ curl_easy_setopt(curl, CURLOPT_COOKIELIST, my_cookie);Get all cookies from the cookie storestruct curl_slist *cookies curl_easy_getinfo(easy, CURLINFO_COOKIELIST, &cookies); /*这将返回指向cookie的链接列表的指针,并且每个cookie(再次)被指定为cookie文件格式的一行。该列表已分配给您,因此在应用程序处理完该信息后,请不要忘记调用curl_slist_free_all*/Cookie store commands//清除整个内存记录 curl_easy_setopt(curl, CURLOPT_COOKIELIST, "ALL"); //从内存中删除所有会话cookie(无有效期的cookie) curl_easy_setopt(curl, CURLOPT_COOKIELIST, "SESS"); //强制将所有cookie写入先前使用CURLOPT_COOKIEJAR指定的文件名 curl_easy_setopt(curl, CURLOPT_COOKIELIST, "FLUSH"); //从先前用CURLOPT_COOKIEFILE指定的文件名强制重新加载cookie curl_easy_setopt(curl, CURLOPT_COOKIELIST, "RELOAD"); DownloadGET方法请求资源easy = curl_easy_init(); curl_easy_setopt(easy, CURLOPT_URL, "http://example.com/"); curl_easy_perform(easy);如果使用其他方法请求资源向切随后换回get请求curl_easy_setopt(easy, CURLOPT_HTTPGET, 1L);下载相应的返回包头数据 用CURLOPT_HEADEReasy = curl_easy_init(); curl_easy_setopt(easy, CURLOPT_HEADER, 1L); curl_easy_setopt(easy, CURLOPT_URL, "http://example.com/"); curl_easy_perform(easy);或者将包头数据存储到文件easy = curl_easy_init(); FILE *file = fopen("headers", "wb"); curl_easy_setopt(easy, CURLOPT_HEADERDATA, file); curl_easy_setopt(easy, CURLOPT_URL, "http://example.com/"); curl_easy_perform(easy); fclose(file);在开发时设置详细模式,将同时显示发送到stderr的传出和传入标头:curl_easy_setopt(easy, CURLOPT_VERBOSE, 1L);获取一个页面存储到内存#include <stdio.h> #include <stdlib.h> #include <string.h> #include <curl/curl.h> struct MemoryStruct { char *memory; size_t size; }; static size_t WriteMemoryCallback(void *contents, size_t size, size_t nmemb, void *userp) { size_t realsize = size * nmemb; struct MemoryStruct *mem = (struct MemoryStruct *)userp; mem->memory = (char*)realloc(mem->memory, mem->size + realsize + 1); if(mem->memory == NULL) { return 0; } memcpy(&(mem->memory[mem->size]), contents, realsize); mem->size += realsize; mem->memory[mem->size] = 0; return realsize; } int main(void) { CURL *curl_handle; CURLcode res; struct MemoryStruct chunk; chunk.memory = malloc(1); chunk.size = 0; curl_global_init(CURL_GLOBAL_ALL); //整个程序全局只需要初始化一次 多次初始化会出问题 curl_handle = curl_easy_init(); curl_easy_setopt(curl_handle, CURLOPT_URL, "https://www.example.com/"); curl_easy_setopt(curl_handle, CURLOPT_WRITEFUNCTION, WriteMemoryCallback); curl_easy_setopt(curl_handle, CURLOPT_WRITEDATA, (void *)&chunk); //curl_easy_setopt(curl_handle, CURLOPT_USERAGENT, "libcurl-agent/1.0"); res = curl_easy_perform(curl_handle); if(res != CURLE_OK) { fprintf(stderr, "curl_easy_perform() failed: %s\n", curl_easy_strerror(res)); } else { printf("%lu bytes retrieved\n", (long)chunk.size); } curl_easy_cleanup(curl_handle); free(chunk.memory); curl_global_cleanup(); return 0; }获取一个文件流的回调函数//下载文件 static size_t Writeback(void* pBuffer, size_t nSize, size_t nMemByte, void* pParam) { //把下载到的数据以追加的方式写入文件(一定要有a,否则前面写入的内容就会被覆盖了) FILE* fp = NULL; fopen_s(&fp, "E:\\test_1.wav", "ab+"); size_t nWrite = fwrite(pBuffer, nSize, nMemByte, fp); fclose(fp); return nWrite; } //如果未设置此回调,则默认情况下libcurl使用'fwriteUploadloadhttp postHTTP请求将数据传递到服务器的标准方法,使用libcurl,通常可以提供该数据作为指针和长度curl_easy_setopt(easy, CURLOPT_POSTFIELDS, dataptr); curl_easy_setopt(easy, CURLOPT_POSTFIELDSIZE, (long)datalength);使用自定义回调函数将不断调用回调函数,直到所有数据都传输或者传输失败 如果未设置此回调,则默认情况下libcurl使用'fread'#include <stdio.h> #include <fcntl.h> #include <sys/stat.h> #include <curl/curl.h> //回调函数的签名 必须按照这个签名实现自己的回调函数 static size_t read_callback(void *ptr, size_t size, size_t nmemb, void *stream) { size_t retcode; curl_off_t nread; retcode = fread(ptr, size, nmemb, stream); nread = (curl_off_t)retcode; fprintf(stderr, "*** We read %" CURL_FORMAT_CURL_OFF_T " bytes from file\n", nread); return retcode; } int main(int argc, char **argv) { CURL *curl; CURLcode res; FILE * hd_src; struct stat file_info; char *file; char *url; if(argc < 3) return 1; file = argv[1]; url = argv[2]; stat(file, &file_info); hd_src = fopen(file, "rb"); curl_global_init(CURL_GLOBAL_ALL); curl = curl_easy_init(); if(curl) { /* we want to use our own read function */ curl_easy_setopt(curl, CURLOPT_READFUNCTION, read_callback); /* enable uploading */ curl_easy_setopt(curl, CURLOPT_UPLOAD, 1L); /* HTTP PUT please */ curl_easy_setopt(curl, CURLOPT_PUT, 1L); /* specify target URL, and note that this URL should include a file name, not only a directory */ curl_easy_setopt(curl, CURLOPT_URL, url); /* now specify which file to upload */ curl_easy_setopt(curl, CURLOPT_READDATA, hd_src); /* provide the size of the upload, we specicially typecast the value to curl_off_t since we must be sure to use the correct data size */ curl_easy_setopt(curl, CURLOPT_INFILESIZE_LARGE, (curl_off_t)file_info.st_size); /* Now run off and do what you've been told! */ res = curl_easy_perform(curl); /* Check for errors */ if(res != CURLE_OK) fprintf(stderr, "curl_easy_perform() failed: %s\n", curl_easy_strerror(res)); /* always cleanup */ curl_easy_cleanup(curl); } fclose(hd_src); /* close the local file */ curl_global_cleanup(); return 0; }HTTP PUT CURLOPT_INFILESIZE_LARGE设置上传的大小curl_easy_setopt(easy, CURLOPT_UPLOAD, 1L); curl_easy_setopt(easy, CURLOPT_INFILESIZE_LARGE, (curl_off_t) size); curl_easy_setopt(easy, CURLOPT_READFUNCTION, read_callback); curl_easy_setopt(easy, CURLOPT_URL, "https://example.com/handle/put"); /*如果不知道在传输之前不知道传输的大小,对于HTTP 1.0,您必须事先提供大小,HTTP 1.1 你可以添加 标头 Transfer-Encoding: chunked 对于HTTP 2及更高版本,则既不需要大小也不需要额外的标头*/